Business Case: Customized Stack zur automatisierten Luftschadstoffprognose in Berlin
Task
Luftschadstoffe haben eine direkte gesundheitsschädigende Wirkung auf den Menschen, sie verursachen beispielsweise Atemwegsprobleme und Herz-Kreislauf-Erkrankungen. Deswegen möchte die Berliner Senatsverwaltung für Mobilität, Verkehr, Klimaschutz und Umwelt (SenMVKU) der Bevölkerung zuverlässige Informationen zu Luftschadstoffkonzentrationen und Grenzwertüberschreitungen zur Verfügung stellen. Dazu benötigt sie ein Prognosemodell. Durch die Modellprognosen bekommen die Bewohner*innen die Möglichkeit, Gebiete mit hoher Luftschadstoffbelastung zu meiden und beispielsweise ihre Jogging-Routen von der Straße in den Park zu verlegen. Außerdem ermöglicht es der Senatsverwaltung wenige Tage im voraus abzuschätzen, wie viel Verkehr gesundheitsverträglich ist und ggf. verkehrslenkende Maßnahmen einzuleiten, um die Schadstoffbelastung zu senken.
Der Auftrag umfasst eine räumliche und zeitliche Luftschadstoffprognose für die Schadstoffe Stickstoffdioxid und Feinstaub in zwei unterschiedlichen Partikelgrößen. Dabei werden - ähnlich einer Wettervorhersage - Prognosen für die nächsten vier Tage in stündlichen Abständen an allen größeren Straßenzügen in Berlin benötigt. Die Prognoseerstellung soll vollautomatisch und robust laufen, auch bei Unregelmäßigkeiten der Datenbereitstellung oder Lücken in den Daten.
Data
Die wichtigste Datenquelle sind Messwerte von Stickstoffdioxid und Feinstaub an den 17 Luftschadstoff-Messcontainern in Berlin seit 2015. Diese Container stehen an ganz unterschiedlichen Orten, von stark befahrenen Straßen über Wohngebiete bis zum Wald. Eine weitere Datenquelle ist die Wetterprognose des Deutschen Wetterdienstes (DWD). Die Daten-Schnittstellen (APIs) für Schadstoffmessungen und Wetterprognose werden stündlich aktualisiert. Neben der Wettervorhersage, gibt es als weitere Datenquelle noch eine großräumige Luftschadstoffprognose des Copernicus-Konsortiums. Diese zeigt die Schadstoff-Hintergrundbelastung an, wie sie beispielsweise am Stadtrand zu beobachten ist. Die Copernicus-Daten werden einmal täglich im Laufe des Vormittags aktualisiert.
Der Verkehr ist einer der Haupttreiber der Schadstoffbelastung in Berlin. Als Basis für eine Prognose des erwarteten Verkehrs dienen zeitlich hochaufgelöste Zähldaten von über 200 Verkehrsdetektoren in ganz Berlin.
Um eine Prognose für Orte zu machen, an denen kein Messcontainer steht, sind Informationen über die Standorte notwendig, zum Beispiel über die Bebauungsdichte und Grünfläche sowie die generelle Verkehrsmenge aus Verkehrszählungen. Um die Prognosen für alle Abschnitte größerer Straßen zu machen, liegen zudem Informationen über alle Straßen in Berlin vor (sog. Detailnetz).
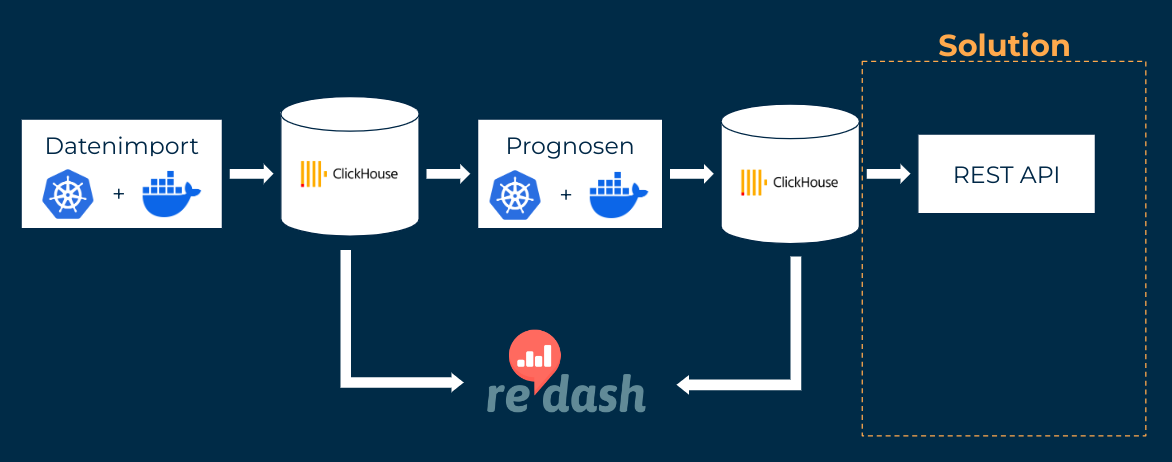
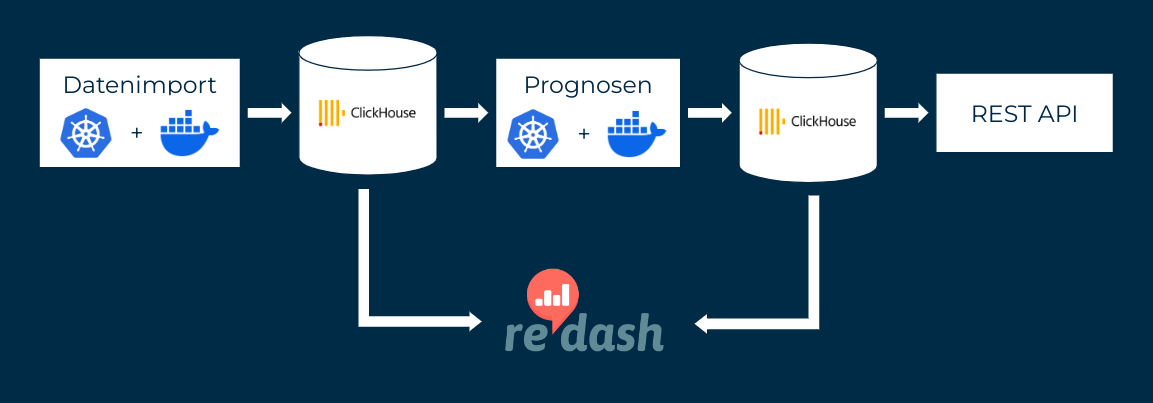
Die regelmäßigen Datenimporte werden über Jobs umgesetzt, die über die Software Kubernetes ausgesteuert werden. Diese Jobs führen Python- oder R-Programmcode aus, der die Daten einliest, kleinere Lücken mit plausiblen Werten befüllt, die Daten in ein einheitliches Format bringt (z.B. bezüglich zeitlicher und räumlicher Auflösung) und in einer Datenbank abspeichert. Dabei handelt es sich um eine ClickHouse Datenbank, die im Umgang mit großen Datenmengen besonders leistungsfähig ist.
Zur Validierung der Daten werden Dashboards der Open-Source-Software Redash verwendet. Redash greift dazu direkt auf die ClickHouse Datenbank zu. Außerdem sind in Redash verschiedene Alarme eingerichtet, die bei Problemen Benachrichtigungen verschicken, z.B. bei verspäteten Datenlieferungen oder größeren Datenlücken.

Analytics
Um das Luftschadstoffniveau der kommenden vier Tage zu prognostizieren, wird ein XGBoost-Modell, ein Machine-Learning-Ansatz, verwendet. Dieser Algorithmus kann nichtlineare Effekte und komplexe Interaktionen aus den Daten extrahieren und für die Prognose verwenden. Beispielsweise lernt das Modell:
- Je stärker der Wind, desto geringer die Schadstoffbelastung. Die Feinstaubbelastung steigt bei extrem starken Winden jedoch wieder an. Dieser zunächst überraschende Zusammenhang wurde durch die Senatsverwaltung bestätigt und ist vermutlich auf Aufwirbelung zurückzuführen.
- Während der Rush Hour ist die Schadstoffbelastung höher, wobei der Peak am Morgen kürzer und stärker ist als am Abend. Diese Peaks sind nur an Werktagen zu beobachten.
- Bei Ostwind ist die Feinstaubbelastung am höchsten, bei Nordwind am niedrigsten. Das liegt daran, dass aus Richtung der See (Norden) wenig Feinstaub eingetragen wird. In den Regionen östlich von Berlin ist am meisten Industrie angesiedelt, die Feinstaub produziert.
Im ersten Schritt werden Prognosen auf einem 50x50m²-Gitter in ganz Berlin erstellt. Diese werden im zweiten Schritt mit Hilfe des Straßen-Detailnetzes auf die Straßenzüge aggregiert.
Mehrmals täglich werden neue Modell-Prognosen auf Basis der neuesten Daten erstellt, ebenfalls mit Kubernetes Jobs. Diese führen einen Python-Code aus, der die konsolidierten Daten aus der Datenbank in ein vortrainiertes Modell einspeist. Die Prognosen werden in einer Produktiv-Datenbank gespeichert.
Zusammenhänge in den Daten können sich mit der Zeit ändern. Beispielsweise kann der Anstieg des E-Auto-Anteils zu einem geringeren Einfluss des Verkehrs auf die Schadstoffbelastung führen. Um die aktuelle Zusammenhangs-Struktur im Modell abzubilden, wird das Modell mit einem monatlichen Kubernetes Job regelmäßig neu trainiert.
Redash Dashboards ermöglichen die Evaluation und Überwachung der Modelle.
Solution
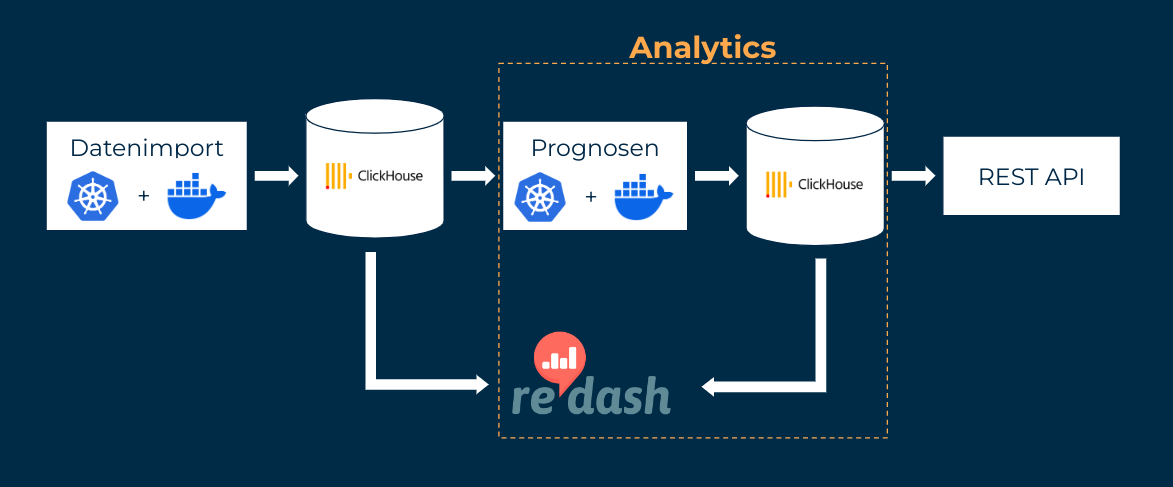
Damit die benötigten Prognosen für alle Schadstoffe regelmäßig und zuverlässig erstellt werden, ist eine komplexe Infrastruktur notwendig. Der verwendete Custom Stack stellt auch von technischer Seite maximale Stabilität sicher: Wenn ein Kubernetes Job abbricht, wird er automatisch neu gestartet, bis eine maximale Anzahl an Versuchen überschritten ist. Vorübergehende Probleme, zum Beispiel mit der Datenbankverbindung, erfordern dadurch kein manuelles Eingreifen. Die Kubernetes Jobs führen den R- und Python-Code stets in Docker Containern aus. Dadurch wird eine stabile Software-Umgebung generiert, in der die Versionen aller verwendeten Programme und Bibliotheken fixiert sind. Damit ist ausgeschlossen, dass automatische Versions-Updates zu Fehlern führen. Beim manuellen Installieren von Updates oder Änderungen am Code stellen automatisierte Tests sicher, dass der Code weiterhin funktioniert wie erwartet. Durch eine strenge Trennung von Entwicklungs- und Produktivumgebung werden Neuentwicklungen erst ausgiebig auf ihre Funktionsfähigkeit getestet, bevor sie für die Öffentlichkeit und die SenMVKU in der Produktivumgebung freigeschaltet werden.
Die neuesten Prognosen werden über eine öffentlich verfügbare Schnittstelle (REST API) zur Verfügung gestellt.
Durch die Bereitstellung dieser maßgeschneiderten Softwarelösung werden Luftschadstoffprognosen zuverlässig und regelmäßig erstellt. Dabei werden fortlaufend die aktuellsten verfügbaren Daten integriert, und kleinere Probleme werden automatisch behoben. Über die API werden die Prognosen der Öffentlichkeit und auch anderen Dienstleistern zugänglich gemacht, beispielsweise für die Erstellung von Visualisierungen.