Continuous Integration: Einführung in Jenkins
In unserem Blogartikel zum Thema Continuous Integration haben wir Ihnen eine Auswahl an CI-Tools vorgestellt – darunter auch das sehr weit verbreitete und breits lange am Markt bestehende Tool Jenkins. Jenkins ist ein webbasiertes, kostenloses Open Source Continuous Integration System, das in Java geschrieben ist. Die Konfiguration, Visualisierung und Auswertung der Projekte erfolgt ausschließlich über den Browser. Eine Besonderheit von Jenkins stellt seine hohe Flexibilität dar: mit derzeit über 1500 Plugins können Konfigurationen individuell gestaltet werden. Grundvoraussetzung für Continuous Integration ist, dass der Code in einem Versionskontrollsystem verwaltet wird. Auch hierbei bietet Jenkins eine große Auswahl an kompatiblen Versionskontrollsystemen.
Installation
Jenkins steht in verschiedenen Versionen zur Verfügung. Zunächst haben Sie die Auswahl zwischen einer Long-Term-Support-Version (LTS) und einer Weekly-Version. Während Jenkins bei der Weekly-Version jede Woche ein Update herausbringt, wird bei der LTS-Version alle drei Monate eine stabile Version veröffentlicht. Die Entscheidung sollte sich dabei an ihren individuellen Präferenzen und Bedürfnissen orientieren. Im nächsten Schritt können Sie zwischen verschiedenen Releases wählen: hier stehen sowohl Installationspakete für die gängigen Betriebssysteme (Windows, Ubuntu/Debian, MacOS) als auch (unter anderem) eine Version für Docker sowie ein Webarchiv (.war) zur Verfügung.
Das für Sie passende Installationspaket können Sie hier downloaden: https://jenkins.io/download/. Unter Debian-basierten Distributionen in Linux können Sie Jenkins via apt installieren. Durch die Installation wird Jenkins als Daemon beim Hochfahren des Systems gelauncht und ein Jenkins User angelegt. Unter Windows müssen Sie lediglich das heruntergeladene Paket öffnen und den Installationsanweisungen folgen. Jenkins lauscht anschließend auf Port 8080, den Sie über Ihren Browser unter http://localhost:8080/ erreichen können, um mit der Konfiguration zu beginnen.
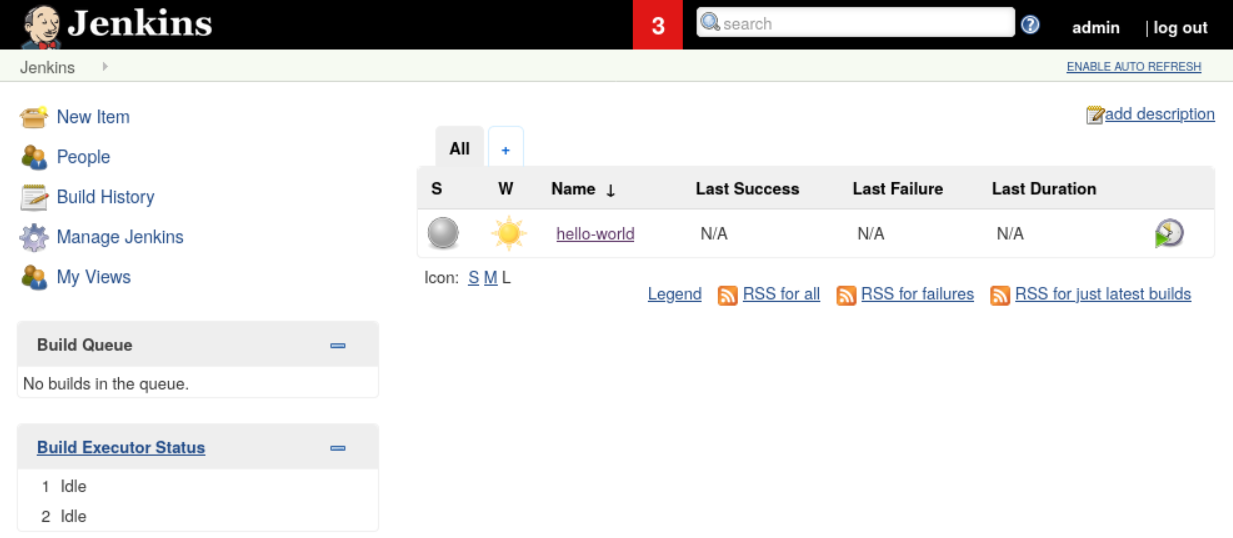
Hier sehen Sie die Startseite von Jenkins. In der Menüleiste auf der linken Seite haben Sie z.B. die Möglichkeit, einen neuen Job anzulegen, Konfigurationen vorzunehmen oder sich die Build-Historie anzuschauen. Darunter sehen Sie die Build-Warteschlange und den Build-Prozessor-Status. Rechts finden Sie eine Übersicht aller existierenden Jobs mit den jeweiligen Informationen zum letzten Erfolg, Fehlschlag und Dauer. Was genau all diese Begriffe bedeuten klären wir in den nächsten Abschnitten.
Erste Schritte mit Jenkins: Erstellen und Konfigurieren von Jobs
Der erste Schritt, um ein Softwareprojekt mit Jenkins zu bauen, besteht darin, einen sogenannten „Job“ in Jenkins anzulegen. Dieser kann verschiedene Aufgaben übernehmen. Innerhalb eines Softwareprojektes gibt es meist mehrere Jobs. Gängig sind beispielsweise Jobs zum Ausführen von Unit Tests oder zum Deployen des Codes. Es gibt grundsätzlich zwei Vorgehensweisen beim Erstellen eines Jobs:
- Sie konfigurieren den Job vollständig über die Klickoberfläche in Jenkins
- Sie erstellen ein Jenkinsfile in einem Versionskontrollsystem wie GitHub, welches Sie anschließend in Jenkins einbinden.
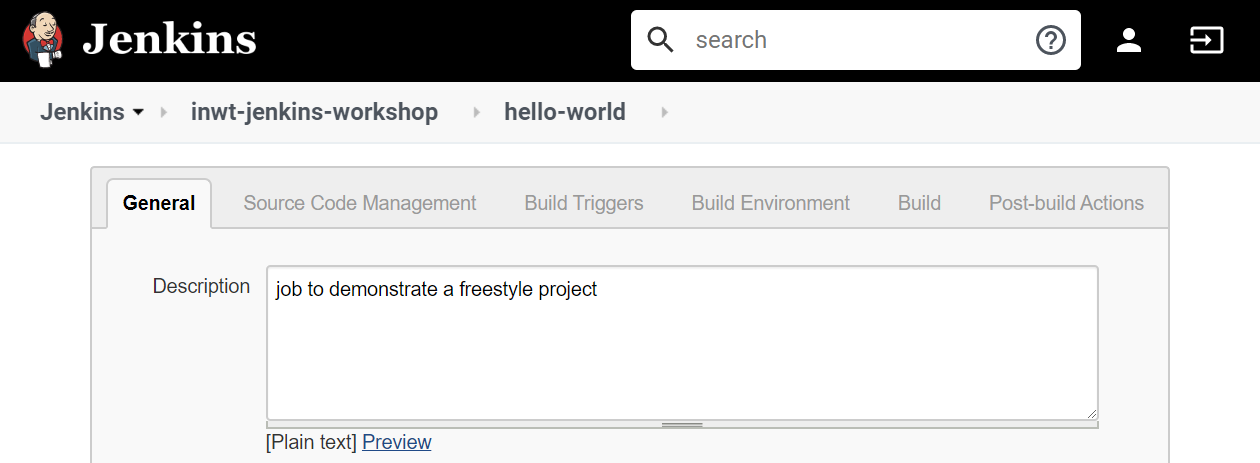
In Jenkins gibt es verschiedene Typen von Jobs, die Sie durch einen Klick auf „New Item“ (bzw. „Element anlegen”) auswählen können. Der gängigste Typ ist das Freestyle Projekt. Hierbei können Sie einen Job vollständig über die Klickoberfläche konfigurieren. Zur Veranschaulichung haben wir einen beispielhaften Freestyle-Job konfiguriert, der „Hello World!” ausgibt:
...
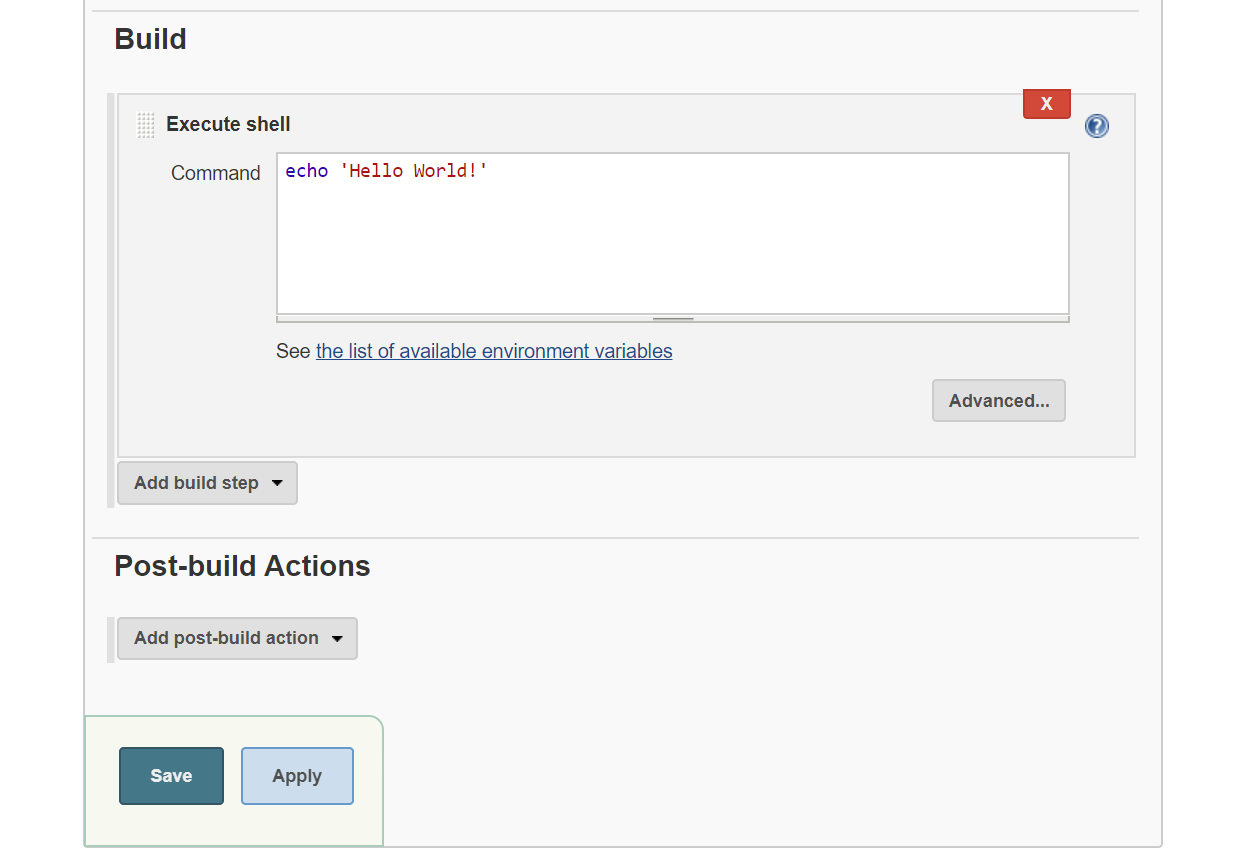
Wie Sie sehen, haben Sie eine große Auswahl an Konfigurationsmöglichkeiten. Der Übersichtlichkeit halber zeigen wir nur einen Teil der Einstellungen. Wir bei INWT nutzen außerdem verschiedene Plugins in Jenkins, weshalb einige dieser Optionen in der Basisinstallation nicht verfügbar sind.
Im Rahmen der Konfiguration kann es zum Beispiel sinnvoll sein, einen Build-Auslöser zu wählen. Dabei hat man beispielsweise die Möglichkeit, den Job zeitgesteuert zu starten (z.B. jeden Tag zu einer bestimmten Uhrzeit) oder ihn in Abhängigkeit von anderen Projekten auszuführen (z.B. nachdem ein anderer Job erfolgreich ausgeführt wurde). In unserem Fall haben wir keinen Build-Auslöser gewählt.
Haben Sie die Konfiguration vorgenommen, kann der Job manuell durch einen Klick auf „Build Now” (bzw. „Jetzt Bauen”) ausgeführt werden. Das einmalige Durchlaufen eines Jobs wird Build genannt. Nachdem der Job durchgelaufen ist, bekommt er im Build-Verlauf eine farbige Markierung, wobei Blau für einen erfolgreichen und Rot für einen fehlerhaften Build steht. Außerdem haben Sie vielleicht schon einmal von der charakteristischen Wettermarkierung (Sonne, Wolken, Gewitter) in Jenkins gehört: sie ist ein Indikator für die allgemeine „Gesundheit“ eines Jobs und wird durch Faktoren wie die Build-Historie oder die Code-Coverage-Ergebnisse beeinflusst.
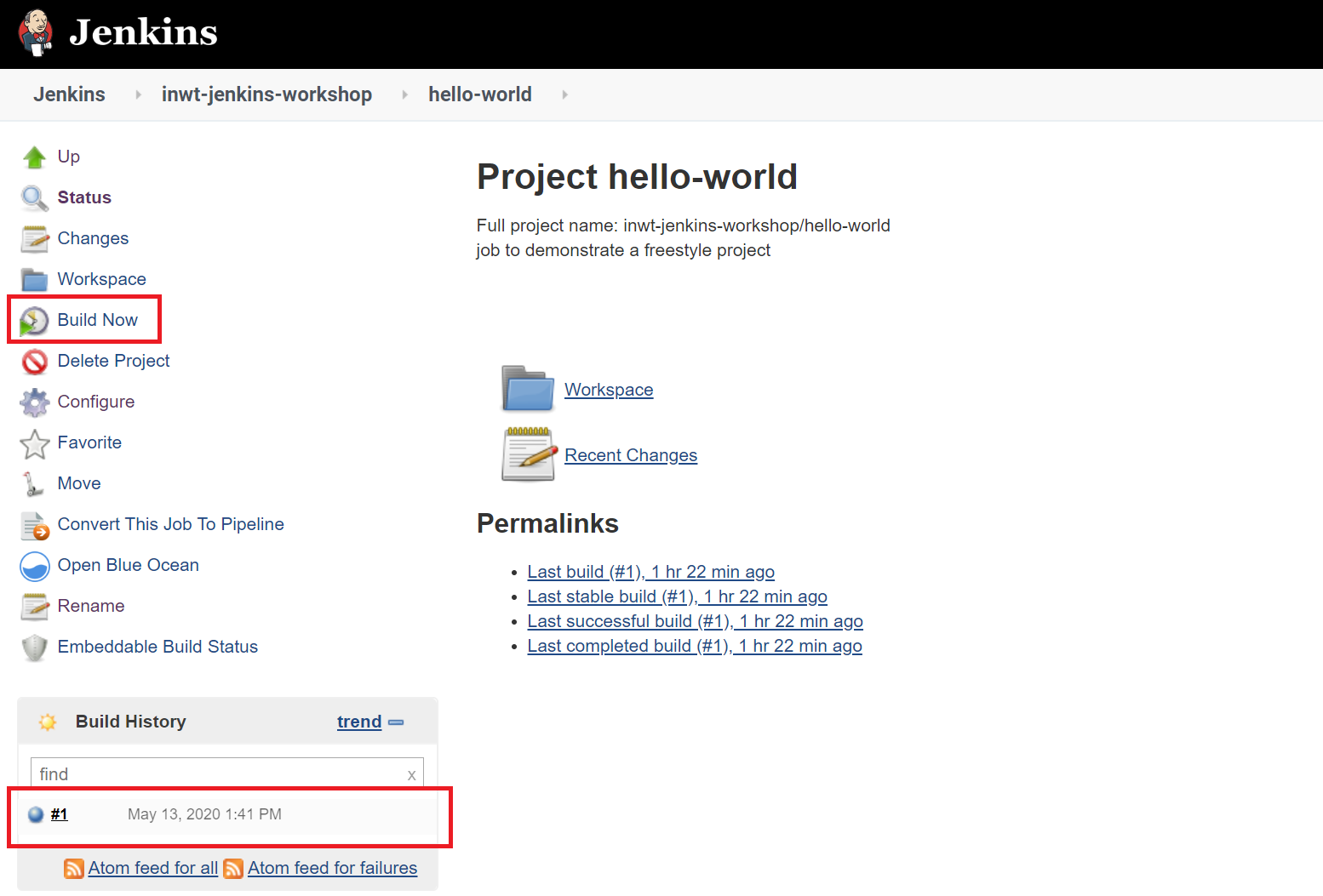
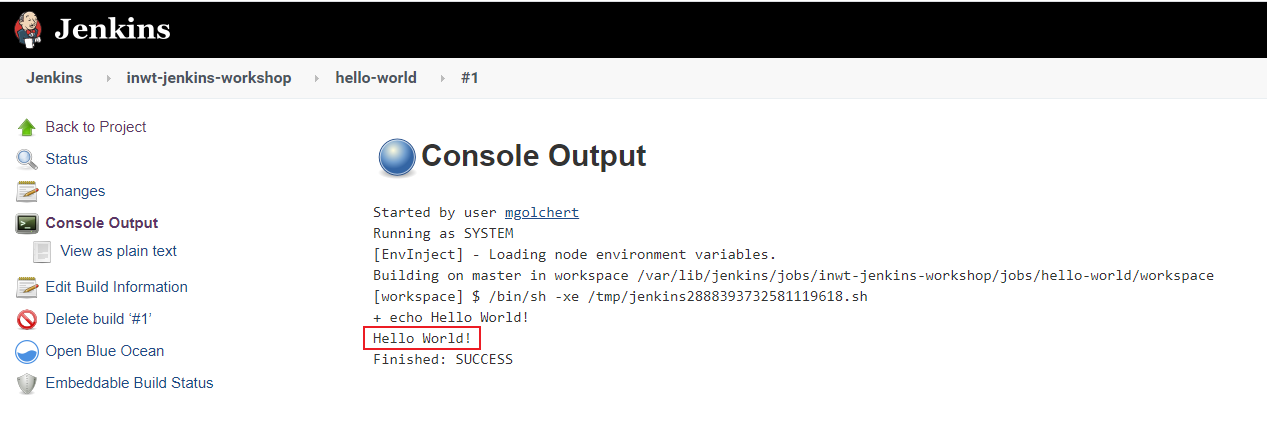
Wir sehen anhand des blauen Punktes dass unser Build erfolgreich war. Durch einen Klick auf den Build sowie auf der darauffolgenden Seite auf “Console Output” gelangen wir zum Konsolenoutput und können sehen, dass der Job “Hello World!” ausgegeben hat.
GitHub Integration in Jenkins
Sie haben in Jenkins die Möglichkeit, ein Source Code Management System wie z.B. GitHub einzubinden. Hierfür sind im Falle von GitHub zunächst das Git-Plugin und anschließend lediglich die Repository URL und entsprechende Credentials erforderlich, um auf den Code im Repository zugreifen zu können. Im einfachsten Fall liegt im Repository ein Jenkinsfile, das beim Starten des Jobs ausgeführt wird. Bei der Wahl der Build-Auslöser haben Sie hierbei die praktische Möglichkeit, den Job bei jedem Commit auf einen definierten Branch zu starten. Diese Einstellung eignet sich insbesondere für Jobs, die Unittests ausführen.
Erstellen eines Pipeline-Jenkinsfiles
In einem Jenkinsfile wird eine Jenkins Pipeline definiert. Pipeline-Jenkinsfiles folgen der Groovy-Syntax. Ein beispielhaftes Jenkinsfile mit minimalem Setup, bei dem ein R-Skript in einem Dockercontainer ausgeführt wird, könnte folgendermaßen aussehen:
pipeline {
agent none
stages {
stage('Pull dockerimage') {
steps {
sh '''
docker pull inwt-jenkins-image
'''
}
}
stage('Run rscript in container') {
steps {
sh '''
docker run --rm --network host \
--name inwt-jenkins-container \
inwt-jenkins-image Rscript inwt-jenkins-rscript.R
'''
}
}
}
}
Eine Pipeline enthält verschiedene Stages, wobei die auszuführenden Befehle im “steps”-Block stehen. In der ersten Stage in unserem Beispiel wird das Dockerimage geladen, während in der zweiten Stage der Container gestartet und ein R-Skript ausgeführt wird.
Wir bei INWT bevorzugen die Möglichkeit der Einbindung von Jenkinsfiles gegenüber der reinen Konfiguration der Jobs über die Klickumgebung. Hierdurch erhöht sich für uns die Übersichtlichkeit, da die Jenkinsfiles an derselben Stelle liegen wie der Code. Außerdem sind sie so für alle Teammitglieder unmittelbar zugänglich und wir können von den Tools der Versionskontrolle wie z.B. Pull Request mit Code Review oder Rollbacks profitieren.
Fazit
Auf Grund der umfangreichen Anwendungs- und Konfigurationsmöglichkeiten von Jenkins könnte der Artikel an dieser Stelle noch eine Vielzahl weiterer Themen behandeln. Jenkins hat sich für den Großteil unserer Data-Science-Projekte als äußerst hilfreiches Tool etabliert, vor allem wenn es um Unit Tests, ETL-Prozesse und Deployments geht. Es ermöglicht uns, manuelle Aufgaben zu automatisieren, fehlerhaften Code frühzeitig zu erkennen, unmittelbar zu reagieren und somit die Qualität des Codes langfristig zu sichern.