Logistische Regression - Modell und Grundlagen
Nach der Artikelserie zur einfachen linearen Regression und der multiplen linearen Regression widmet sich diese Artikelserie der logistischen Regression (kurz: Logit Modell). Das Logit-Modell ist ein extrem robustes und vielseitiges Klassifikationsverfahren. Es ist in der Lage, eine abhängige binäre Variable zu erklären und eine entsprechende Vorhersage der Wahrscheinlichkeit zu treffen, mit der ein Ereignis eintritt oder nicht. Die folgenden Beispiele verdeutlichen das Spektrum möglicher Anwendungen:
- Conversion-Prognose: Kauft ein Kunde ein Produkt?
- Bonität: Zahlt ein Kreditnehmer einen Kredit vollständig zurück?
- Markenbekanntheit: Kennt jemand eine Marke?
- Parteipräferenz: Würde eine Person Partei X wählen, wenn am kommenden Sonntag Bundestagswahlen wären?
- Medizinische Diagnose: Hat eine Person eine bestimmte Krankheit?
- Qualitätskontrolle: Entspricht ein Produkt der Spezifikation?
- Einschaltquoten: Hat eine Person eine TV-Sendung gesehen?
- A/B-Testing: Ist Version A einer Webseite besser als eine Version B?
- ...
Obwohl die zu erklärende Variable binär ist (also zwei Ausprägungen besitzt, z.B. ja oder nein, krank oder nicht-krank, besser/genauso gut oder schlechter, ...), kann das Logit-Modell über die reine Klassifikation hinaus auch eine Wahrscheinlichkeit dafür prognostizieren, dass eine Untersuchungseinheit einer Gruppe angehört (z.B. eine Person wird den Kredit mit einer Wahrscheinlichkeit von 95% zurückzahlen). Die Methodik entspricht dabei weitgehend der der linearen Regression - Hauptunterschied ist, dass bei der linearen Regression die abhängige Variable metrisch ist, während sie beim Logit Modell diskret (genauer gesagt: binär) ist.
Was ist der Unterschied zwischen einer metrischen und einer binären Variable?
Metrische Variable: Die Abstände der einzelnen Werte sind interpretierbar und es besteht eine Rangfolge zwischen ihnen. Beispiel: Gewicht, Reaktionszeiten, Geldbeträge, ...
Binäre Variable: Die Variable hat genau zwei Ausprägungen. Beispiel: Geschlecht (männlich, bspw. kodiert als 0; weiblich, bspw. kodiert als 1)
Vielleicht stellen Sie sich an diesem Punkt die Frage, warum eine lineare Regression für die Modellierung von binären abhängigen Variablen nicht die optimale Methode ist. Würde man die Wahrscheinlichkeit für ein beliebiges Ereignis Y=1 mittels eines einfachen linearen Regressionsmodells bestimmen, sähe dieses Modell grafisch folgendermaßen aus:

Das zugehörige lineare Regressionsmodell lautet:

Eine einfache lineare Regression modelliert die Werte, die sich auf der roten Regressionsgerade befinden. Theoretisch ist ihr Wertebereich [-∞,∞]. Wie in der oberen Grafik zu sehen ist, nehmen die Werte der abhängigen Variablen aber nur die Werte 0 und 1 an. Aus diesem Grund ist es sinnvoll, den Wertebereich für die Vorhersagen auf den Bereich [0,1] zu beschränken und folglich mit Wahrscheinlichkeiten zu arbeiten.
Konkret treten folgende Probleme bei der Modellierung einer binären abhängigen Variablen durch eine lineare Regression auf:
- Die linke Seite der Regressionsgleichung ist binär (es treten nur die Werte 0 und 1 auf), die rechte Seite ist metrisch skaliert.
- Das lineare Regressionsmodell gibt auch Werte <0 und >1 aus, was für die Modellierung einer Wahrscheinlichkeit unzweckmäßig ist.
- Die Residuenvarianz ist nicht homoskedastisch, d.h. die Varianz (σ²) der beobachteten Größe einer Beobachtung i ist von ihrem Niveau ( πi ) abhängig.
 Wobei πi die Wahrscheinlichkeit für das Ereignis für die i-te Beobachtung im Datensatz ist. Dies ist der Fall, da die abhängige Variable der Bernoulliverteilung folgt.
Wobei πi die Wahrscheinlichkeit für das Ereignis für die i-te Beobachtung im Datensatz ist. Dies ist der Fall, da die abhängige Variable der Bernoulliverteilung folgt.
Um diese Probleme zu beseitigen, wird eine Funktion auf die rechte Seite der Gleichung angewendet, deren Zweck es ist, den unbeschränkten Wertebereich der linearen Funktion auf den Bereich 0 bis 1 zu transformieren. Infrage kommende Funktionen sollten streng monoton steigend sein und den Bereich der reellen Zahlen auf das Intervall 0 bis 1 abbilden.
Für den Statistiker naheliegend ist die Nutzung verschiedener Verteilungsfunktionen, die genau diese Eigenschaften mitbringen. Bei der Verwendung der logistischen Verteilungsfunktion F(η), (wobei η = griech. Buchstabe "Eta")

ergibt sich das sogenannte Logit-Modell. η wird auch als Linkfunktion bezeichnet, da es im Folgenden das Regressionsmodell mit den vorhergesagten Wahrscheinlichkeiten verknüpft (siehe nächster Abschnitt). Die Abbildung unten zeigt das Logit-Modell für dieselben Daten, die im oberen Abschnitt schon mittels einfacher linearer Regression modelliert wurden, die logistische Verteilungsfunktion ist rot dargestellt.

Eine Alternative zur logistischen Verteilungsfunktion stellt die Verteilungsfunktion der Normalverteilung dar. Wird diese verwendet, so ergibt sich das Probit-Modell. Das Logit-Modell wird dem Probit-Modell jedoch häufig vorgezogen, da die Regressionskoeffizienten einfacherer interpretiert werden können.
Das logistische Regressionsmodell
Das logistische Regressionsmodell zielt darauf ab, mithilfe der logistischen Verteilungsfunktion den Effekt der erklärenden Variablen xi1, ..., xik (i = 1, ..., n) auf die Wahrscheinlichkeit für Yi = 0 bzw. Yi = 1 zu bestimmen.

Wobei die logistische Verteilungsfunktion F(ηi) die sog. Responsefunktion darstellt. ηi (Eta) hingegen wird als Linkfunktion bezeichnet, weil sie eine Verknüpfung (Link) zwischen der Eintrittswahrscheinlichkeit πi und den unabhängigen Variablen herstellt.

mit 
Dementsprechend wird die Wahrscheinlichkeit für Y = 1 nicht direkt aus den erklärenden Variablen modelliert (so wie bei der linearen Regression), sondern indirekt über das sogenannte Logit. Das Logit ist die logarithmierte Chance für das Auftreten von Y = 1.

Die Chance
 wird auch als Odds bezeichnet.
wird auch als Odds bezeichnet.
Was ist der Unterschied zwischen einer Chance und einer Wahrscheinlichkeit?
Eine Fußballmannschaft gewinnt im Durchschnitt eines von drei Spielen.
Ihre Wahrscheinlichkeit zu gewinnen ist: Anzahl der siegreichen Spiele / Anzahl gespielter Spiele = 1/3 = 33,3 %.
Die Chance eines Sieges hingegen ist das Verhältnis der Eintrittswahrscheinlichkeit eines Sieges zur Gegenwahrscheinlichkeit (einer Niederlage). Wahrscheinlichkeit eines Sieges / Wahrscheinlichkeit einer Niederlage = 1/3 / 2/3 = 1/2 oder 1:2. Eine Chance von 1:2 sagt in diesem Fall aus, dass die Mannschaft erwartungsgemäß von drei Spielen eines gewinnt und zwei verliert.
Interpretation der Koeffizienten
Aufgrund des nichtlinearen und indirekten Einflusses der erklärenden Variablen auf die Eintrittswahrscheinlichkeit πi für Yi = 1 können die geschätzten Koeffizienten nicht wie beim linearen Regressionsmodell als direkte Einflussfaktoren auf die Wahrscheinlichkeit πi für Yi = 1 interpretiert werden. Lediglich die Vorzeichen der einzelnen geben unmittelbar Aufschluss über die Wirkungsrichtung: Bei einem negativen Vorzeichen verringert sich die Wahrscheinlichkeit für das Eintreten von Yi = 1 mit steigenden Werten der erklärenden Variable und umgekehrt.
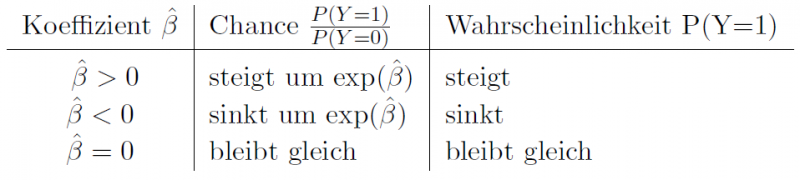
Das Logit ermöglicht jedoch noch eine konkretere Aussage über die Stärke des Einflusses. Diese bezieht sich jedoch nicht auf die Wahrscheinlichkeit, sondern auf die Chance, also die Odds: Erhöht sich der Wert der j-ten erklärenden Variable um den Wert 1, so verändert sich die Chance um den Faktor exp(βj):

Klassifikation über Schwellenwert
Mithilfe der Responsefunktion F(ηi) kann - nach der Schätzung der Regressionskoeffizienten - für jede Beobachtung i die Wahrscheinlichkeit für Yi = 1 bzw. Yi = 0 geschätzt werden. Um auch eine Klassifikation vornehmen zu können, wird ein Schwellenwert verwendet, der standardmäßig bei 0.5 liegt: Ist die geschätzte Wahrscheinlichkeit für Yi = 1 größer (oder gleich) 0.5, so wird die i-te Beobachtung als 1 klassifiziert, sonst wird von 0 ausgegangen.
Beispiel: Conversion-Prognose
Gehen wir als Beispiel von einer Conversion-Prognose aus. Y sei eine binäre Variable mit den Ausprägungen 0 = "Kunde kauft nicht" und 1 = "Kunde kauft". Wir schauen uns zwei Kunden aus dem Datensatz an. Gehen wir davon aus, dass sich für den Kunden mit der Nr. 23 eine Kaufwahrscheinlichkeit von 45% ergibt, also F(η23) = 0.45. Da die geschätzte Wahrscheinlichkeit < 0.5 ist, würden wir vorhersagen, dass es sich beim 23. Kunden um einen Nicht-Käufer handelt. Für den Kunde Nr. 56 hingegen, prognostiziert das Modell eine Kaufwahrscheinlichkeit von 63%, also F(η56) = 0.63. Wegen 0.63 > 0.5 gingen wir davon aus, dass es sich bei dem 56. Kunden um einen Käufer handelt.
Der Schwellenwert kann (innerhalb des Intervalls 0 bis 1) beliebig angepasst werden. Eine Verschiebung des Schwellenwerts hat Einfluss auf die Klassifikationsgüte des Modells. Häufig erfolgt die Anpassung gezielt, um die Klassifikationsgüte hinsichtlich vorgegebener Kriterien zu optimieren. Die Messung der Klassifikationsgüte ist Gegenstand des 2. Teils in unserer Artikelserie zum Logit-Modell.

