Predictive LLMs: Die Rolle multimodaler Daten bei der Preisprognose
In unserem letzten Beitrag haben wir dokumentiert, wie Large Language Models (LLMs) durch gezieltes Finetuning Regressionsaufgaben wie die Vorhersage von Gebrauchtwagenpreisen übernehmen können. Wir konnten zeigen, dass die Kombination aus tabellarischen Merkmalen und Freitext-Beschreibungen die Prognosegüte deutlich steigert. Dennoch blieb ein wichtiger Faktor unberücksichtigt: der visuelle Eindruck des Fahrzeugs.
Eine potenzielle Käuferin bewertet ein Auto selten allein auf Basis von Kilometern und Ausstattungsmerkmalen; die Entscheidung fällt auch auf Basis des Aussehens. In diesem Artikel untersuchen wir daher die nächste Feature-Erweiterung: Inwiefern verbessert die Integration von Bildern im Rahmen einer multimodalen Architektur die Genauigkeit der Preisschätzung?
Der methodische Ansatz: Text, Tabellen und Bilder als kombinierte Features
In unserem aktuellen Versuchsaufbau haben wir die Fahrzeugbilder zunächst direkt in den Trainingsprozess integriert. Die Herausforderung besteht darin, eine Architektur zu schaffen, die sowohl strukturierte Daten (Baujahr, Kilometerstand) als auch unstrukturierte Informationen (Beschreibungstexte und Fotos) effizient verknüpft. Ziel ist es, dass das Modell lernt, den optischen Gesamteindruck sowie visuelle Details wie den Zustand des Lacks, die Optik der Felgen oder auch visuelle Hinweise auf mögliche Schäden des Autos in die ökonomische Bewertung einzubeziehen.
Technisch lässt sich eine solche multimodale Verarbeitung heute über Schnittstellen wie die OpenAI API realisieren. Hierbei ist es möglich, Textprompts und Bilddaten simultan an das Modell zu übermitteln, um eine ganzheitliche Antwort zu generieren. Damit die Bilder über die API übertragen werden können, werden sie im Vorfeld "base64" kodiert. Bei diesem Encoding-Verfahren wird die Bilddatei in eine Textsequenz aus ASCII-Zeichen übersetzt, was den zuverlässigen Versand innerhalb standardisierter JSON-Anfragen ermöglicht.
Für das Finetuning mit Bildern nutzen wir das OpenAI Modell mit der Bezeichnung “gpt-4o-2024-08-06”. Es handelt sich also um eine Variante von gpt-4o - sie wird in der Dokumentation für diesen Zweck empfohlen.
Um den Mehrwert der Bilddaten zu messen, haben wir verschiedene Szenarien verglichen. Als Baseline dient TabPFN, ein Foundation-Modell, das speziell auf Tabellen-Daten optimiert ist.
Die Ergebnisse im Vergleich
Tabelle 1 stellt die Gütemaße für verschiedene Modellkonfigurationen gegenüber. Wir betrachten hierbei den Median Absolute Percentage Error (MAPE), den Median Absolute Error (MAE) und das R2 berechnet auf Testdaten, um ein realistisches Bild der Abweichung zu erhalten. Verglichen werden die Prognosen nach dem Finetuning von GPT-4o mit TabPFN Prognosen.
Die Ergebnisse von GPT-4o basieren auf einem Trainingsdatensatz für das Finetuning von 360 Beobachtungen, während für die TabPFN Prognose ca 1400 Trainingsbeobachtungen berücksichtigt werden. Ein Finetuning inklusive der Bilder über die OpenAI API kostet so ca. 12 $.
| Modell | Median Absolute Error (MAE) | Median Absolute Percentage Error (MAPE) | R² Score |
|---|---|---|---|
| GPT-4o (Bilder + Freitext + Tabular) | 700 € | 16.76 % | 0.90 |
| GPT-4o (Freitext + Tabular) | 801 € | 17.92 % | 0.89 |
| TabPFN (Tabular mit Bild-Score Feature) | 1054 € | 21.88 % | 0.85 |
| TabPFN (nur Tabular) | 1081 € | 22.03 % | 0.84 |
| GPT-4o (nur Bilder) | 1400 € | 33.33 % | 0.73 |
Tabelle 1: Prognosemetriken mit verschiedenen Modellen auf dem gleichen Testdatensatz.
Zusammenfassung der Ergebnisse
Die Metriken ermöglichen einen Vergleich der Modellperformanz:
- Informationsgehalt der Bilddaten: Die Hinzunahme von Bildern bewirkt eine Senkung des Medians der absoluten Fehler um 101 €. Dies bestätigt die Vermutung, dass Bilder Informationen enthalten, die weder in der tabellarischen Ausstattung noch in der Textbeschreibung explizit erwähnt werden. Insbesondere waren in den tabellarischen Features keine konsistenten Informationen zu äußerlichen Merkmalen wie dem Lackzustand enthalten.
- Wert der unstrukturierten Daten durch LLMs nutzbar: Während TabPFN eine solide Leistung auf metrischen und kategorialen Daten zeigt, verdeutlicht der Sprung zu den LLM-basierten Modellen den Wert unstrukturierter Daten. Bereits die Fähigkeit des LLMs, den Text der Fahrzeugbeschreibung zu "verstehen", führt zu einer deutlich präziseren Schätzung (vgl. Ergebnis “GPT-4o (Tabular + Freitext)” vs. TabPFN)
- Potenzial mit Bildern alleine: Auch wenn die Prognosen, die nur auf Basis der Bilder erstellt wurden, nicht mit den anderen Ergebnissen mithalten können: Ein R2 von 0,73 ist trotzdem ein Ergebnis, mit dem die Prognose einen Mehrwert bringen kann, wenn eine Preiseinschätzung vorgenommen werden soll. Somit zeigt sich das Potenzial der multimodalen Modelle, auch Prognosen erstellen zu können, wenn im Datensatz ausschließlich Bilder vorliegen.
Kreuzvalidierung und Erklärbarkeit der Ergebnisse
Um eine Generalisierbarkeit zu gewährleisten, ist es bei kleineren Datensätzen Standard, eine Kreuzvalidierung durchzuführen. Dadurch wird vermieden, dass das Ergebnis von der Wahl des Test-Trainsplits abhängig ist.
Ein vielfaches Finetuning mit den Bildern würde aber einige Kosten erzeugen und ist durch die Wartezeiten beim Finetuning wenig komfortabel. Daher haben wir einen anderen Weg gewählt und aus den Bildern ein Feature erzeugt, das das Aussehen des Fahrzeuges auf einer Skala von 1-10 bewertet. In einer Kreuzvalidierung mit TabPFN zeigt sich, dass das Feature einen signifikanten Mehrwert bringt. Auf 25 von 30 Splits sinkt der MAE durch das Feature. Im Durchschnitt über die Splits verringert sich der MAE um 58€, wenn auch im Fall des Splits von Tabelle 1 nur um 27€.
Daraus schließen wir, dass auch der beobachtete Vorteil des Finetunings mit GPT-4o inklusive der Bilder (Tabelle 1) generalisierbar ist.
Bei Betrachtung einzelner Bilder ist zu sehen, dass zum Beispiel ein Auto mit Unfallschaden einen besonders niedrigen Score bekommt, wogegen ein Auto mit Flügeltüren und sehr hochwertigem Lack einen sehr hohen Score bekommt.
Abbildung 1 zeigt außerdem die individuellen Prognosefehler pro Dezil der wahren Preise im Testset für die Modellversion mit Bildern, die die besten Gesamtmetriken in Tabelle 1 erzeugt hat. Im obersten Dezil der Preise ist eine Tendenz zur Unterschätzung zu sehen.
Gleichzeitig ergibt unsere Analyse, dass die Bilder im obersten Dezil zu einer stärkeren Verbesserung geführt haben als insgesamt. So zeigt Abbildung 2, dass sich der MAE im obersten Dezil am meisten verringert im Vergleich “mit Bild” vs. “ohne Bild”. Wir beobachten außerdem, dass in diesem Bereich meistens nach oben korrigiert wurde, falls die Prognose verbessert wurde. Der Tendenz zum Unterschätzen im obersten Dezil wird also etwas entgegengewirkt.
Somit ermöglicht ein Bild für höherpreisige Autos eine Verbesserung der Prognose, wenn z.B. der Lack besonders gut aussieht und der Preis ohne Bilder unterschätzt worden ist. Für niedrigpreisige Autos ist es dagegen nicht so eindeutig.
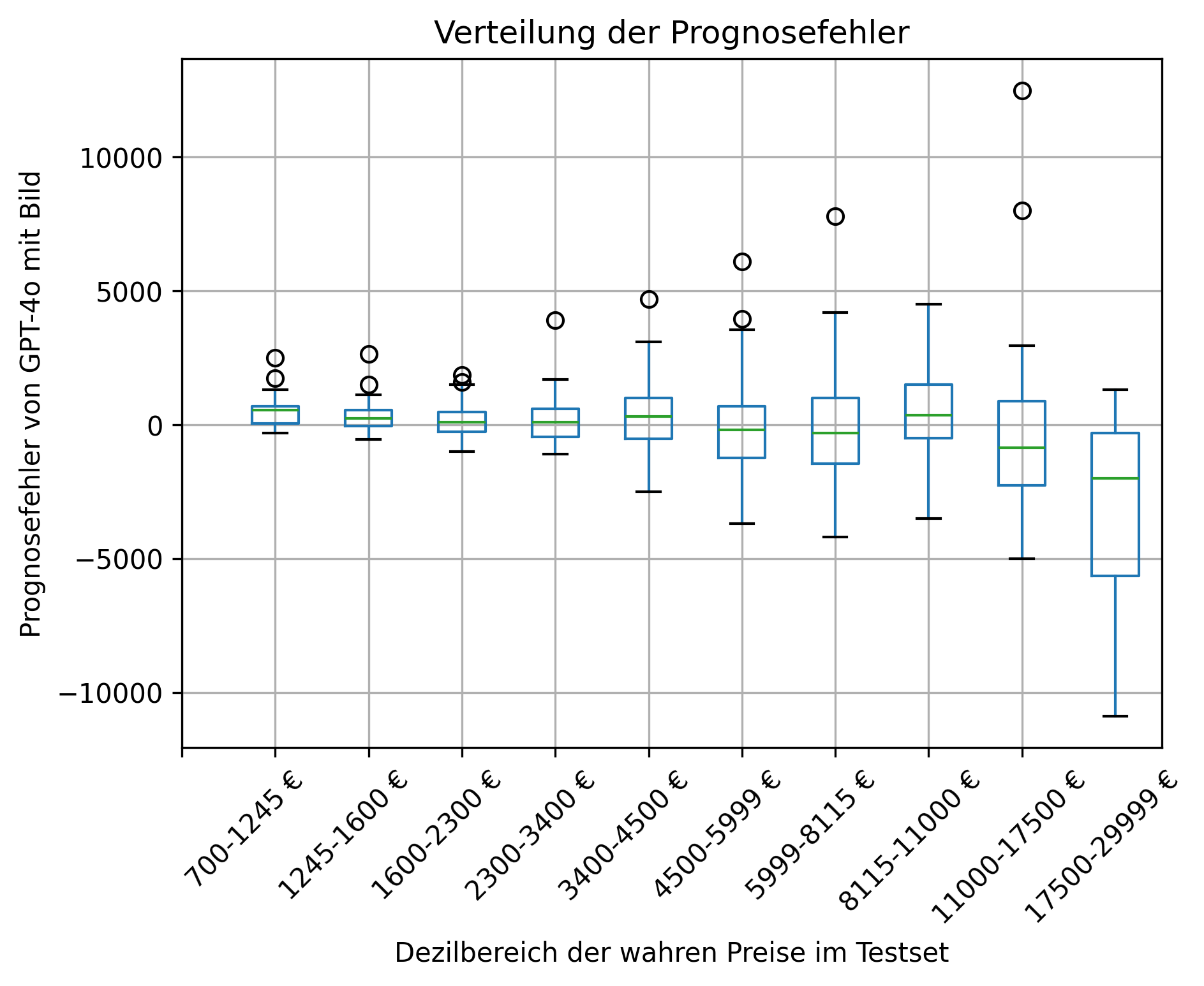 Abbildung 1: Prognosefehler nach Dezil der wahren Werte im Testset. Prognosemodell: GPT-4o (Bilder + Freitex + tabulare Feature).
Abbildung 1: Prognosefehler nach Dezil der wahren Werte im Testset. Prognosemodell: GPT-4o (Bilder + Freitex + tabulare Feature).
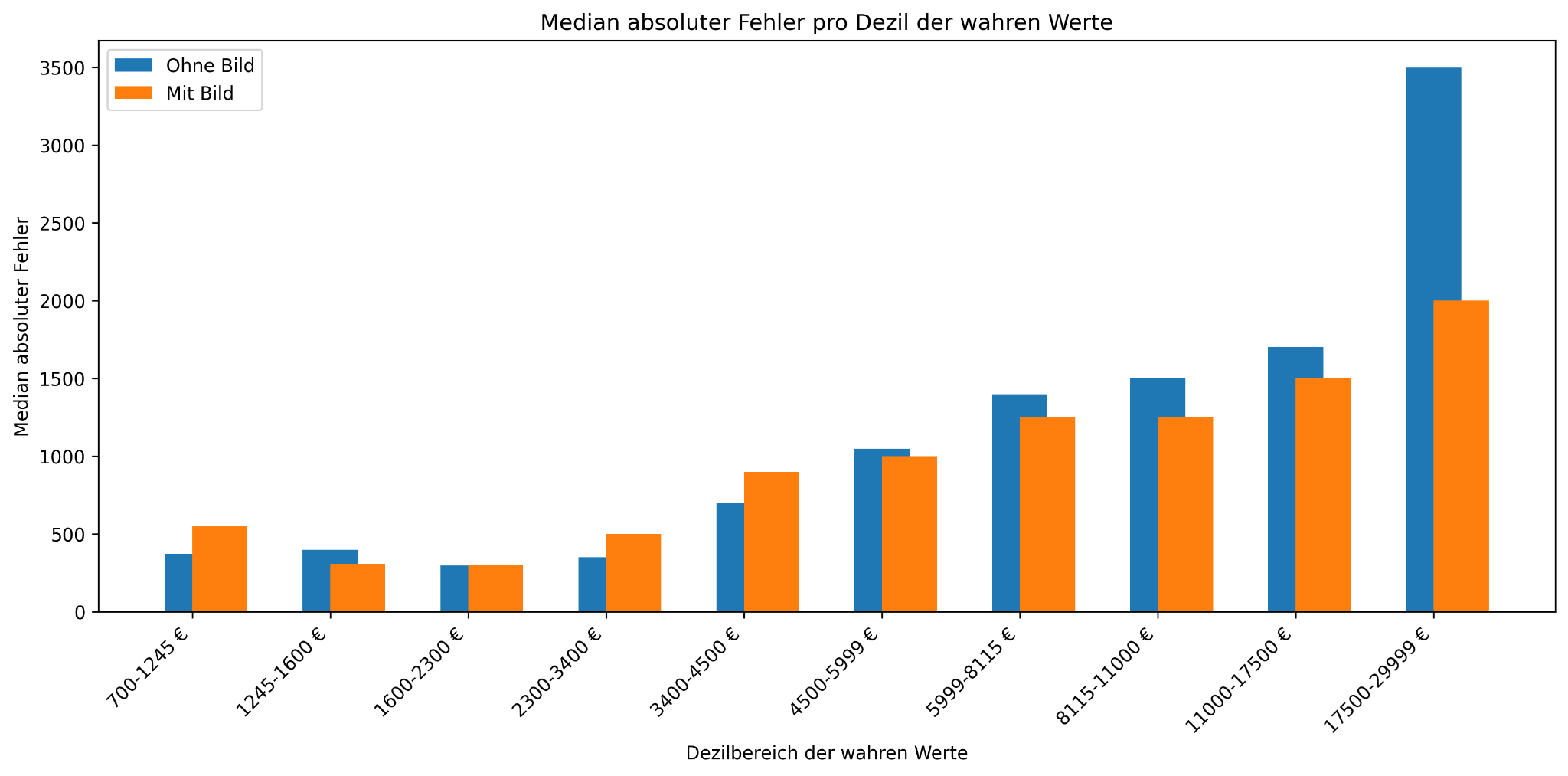 Abbildung 2: Median absoluter Fehler nach Dezil der wahren Werte im Testset. Verglichen wird GPT-4o mit Bildern + Beschreibung + tabulare Feature vs. GPT-4o mit Beschreibung + tabulare Feature.
Abbildung 2: Median absoluter Fehler nach Dezil der wahren Werte im Testset. Verglichen wird GPT-4o mit Bildern + Beschreibung + tabulare Feature vs. GPT-4o mit Beschreibung + tabulare Feature.
Diskussion und Ausblick
Bilder sind eine zusätzliche Informationsquelle, die als Feature nutzbar ist. Dabei stellt sich die Frage der Interpretierbarkeit. Können wir zum Beispiel sichtbar machen, welche Bildbereiche das Modell zur Preisfindung heranzieht? Die gleichzeitige Nutzung von Bild und Text in einem Prompt erschwert diese Aufgabe.
Eine vielversprechende Möglichkeit ist das Erzeugen von tabellarischen Features im Vorhinein, pro Bild und ohne Finetuning. In unserem Fall zeigte die Kreuzvalidierung mit TabPFN, dass die Bilder durch das Score-Feature zur optischen Bewertung einen Mehrwert bieten.
Dies hat den kleinen Nachteil, dass wir bereits wissen oder vermuten müssen, welche Aspekte auf dem Bild für das Modell besonders wertvoll für die Prognose sind. Außerdem ist die Güte der Prognosen deutlich besser, wenn das LLM-Finetuning angewendet wird.
Der Vorteil der Feature-Generierung liegt allerdings in einer verbesserten Nachvollziehbarkeit der LLM-Ergebnisse: Die Plausibilität der LLM-Bewertung lässt sich so zumindest stichprobenartig pro Bild prüfen.
Für eine optimale Prognosegüte zeigt unser Test, dass ein Finetuning verwendet werden sollte. Die Feature-Generierung und Verwendung in TabPFN ermöglicht dafür eine verbesserte Nachvollziehbarkeit der Bildergebnisse und lässt gleichzeitig eine umfassendere Kreuzvalidierung zu.
Zusammenfassend ist die Integration bildbasierter Features ein wichtiger Schritt hin zu einer realistischeren Preisprognose. Für die Praxis bedeutet dies, dass die Qualität der Bilddaten nicht nur für die menschliche Wahrnehmung, sondern zunehmend auch für die algorithmische Bewertung zum Faktor wird.