Eine Einführung in das R-Paket kafka
Apache Kafka ist dafür bekannt, große Datenströme mühelos in Echtzeit zu verarbeiten. Dabei können bereits einfache Cluster beeindruckende Mengen bewältigen. Zusätzlich speichert Kafka Datenkopien ab und bewahrt sie auf, sodass Verluste nahezu ausgeschlossen sind.
Es überrascht daher nicht, dass viele große Unternehmen auf diese Software setzen. Im Rahmen eines Projektes stellten wir aber fest, dass es zwar eine Kafka-Integration für Python, jedoch keine für R gibt.
Mit der Entwicklung des kafka-Pakets ist diese Lücke nun geschlossen. Im Folgenden möchten wir seine Funktionsweise anhand eines Anwendungsbeispiels demonstrieren.
Hands-on mit kafka: Wo befindet sich die ISS?
Initial setzen wir ein eigenes Cluster auf. Die Schritte können in unserem README nachvollzogen werden. Die neueste Paketversion installiert man wie folgt von GitHub:
remotes::install_github("inwtlab/r-kafka")
ISS-Standorte generieren
library(httr)
library(jsonlite)
library(kafka)
config <- list(
"bootstrap.servers" = "localhost:9093"
)
producer <- Producer$new(config)
while (TRUE) {
response <- GET("http://api.open-notify.org/iss-now.json")
json_content <- content(response, as = "parsed", encoding = "UTF-8")
json_string <- toJSON(json_content, auto_unbox = TRUE)
producer$produce("iss", json_string)
Sys.sleep(3)
}
Zunächst richten wir die Verbindungseinstellung für unser Cluster ein und definieren eine Producer-Klasse. Wir verwenden Echtzeitstandortdaten der ISS (International Space Station), welche in etwa alle 3 Sekunden von der Open-Source-API gewonnen werden. Die Daten werden noch dekodiert und als JSON formatiert, bevor sie in das Kafka-Topic gelangen. Dieser Prozess wiederholt sich alle 3 Sekunden. An dieser Stelle möchten wir darauf hinweisen, dass Kafka weitaus mehr leisten kann, als wir in unserem Beispiel zeigen.
ISS-Standorte konsumieren
library(shiny)
library(leaflet)
library(jsonlite)
library(kafka)
ui <- fluidPage(
leafletOutput("iss_map", height = "80vh")
)
server <- function(input, output, session) {
consumer <- Consumer$new(list(
"bootstrap.servers" = "localhost:9093",
"group.id" = paste(sample(letters, 10), collapse = ""),
"enable.auto.commit" = "True"
))
consumer$subscribe("iss")
iss_position <- reactive({
on.exit(invalidateLater(0))
message <- result_message(consumer$consume(5000))
if (!is.null(message$value)) {
data <- fromJSON(message$value)
list(
latitude = as.numeric(data$iss_position$latitude),
longitude = as.numeric(data$iss_position$longitude)
)
}
})
output$iss_map <- renderLeaflet({
leaflet(options = leafletOptions(zoomSnap = 0.1, zoomDelta = 0.1)) %>%
addProviderTiles(providers$Esri.WorldImagery) %>%
setView(lng = 0, lat = 0, zoom = 2.3)
})
observe({
if (is.null(iss_position())) {
return()
}
leafletProxy("iss_map") %>%
clearMarkers() %>%
addMarkers(
lng = iss_position()$longitude,
lat = iss_position()$latitude,
icon = makeIcon(
iconUrl = "https://img.icons8.com/?size=100&id=7ThZQJ5wZJ2T&format=png&color=000000",
iconWidth = 30, iconHeight = 30
)
)
})
session$onSessionEnded(function() {
consumer$close()
})
}
shinyApp(ui = ui, server = server)
Der vorangehende Code zeigt, wie eine einfache Shiny-App die Standortdaten konsumiert und verarbeitet. Den Output lassen wir uns auf einem einzelnen Leaflet anzeigen. Im Shiny-Server definieren wir unsere Consumer-Klasse. Dabei wird die group.id bei App-Start neu generiert. So können wir sicherstellen, dass alle Daten bei Aufruf der App zur Verfügung stehen. Indem wir es abonnieren, verbinden wir den Consumer mit dem Topic. In einer reaktiven Umgebung werden Nachrichten maximal 5 Sekunden lang konsumiert. Da der Prozess in invalidateLater eingebettet ist, wird er danach unmittelbar erneut angestoßen. Sobald ein neues Standortpaar vorliegt, wird die Leaflet-Karte neu gerendert und der Shiny-Observer übernimmt diese Werte, sodass sich der Marker bewegt. Die Verbindung zum Cluster schließt automatisch, wenn die App verlassen wird.
Im Ergebnis kann der Standort visuell nachverfolgt werden:
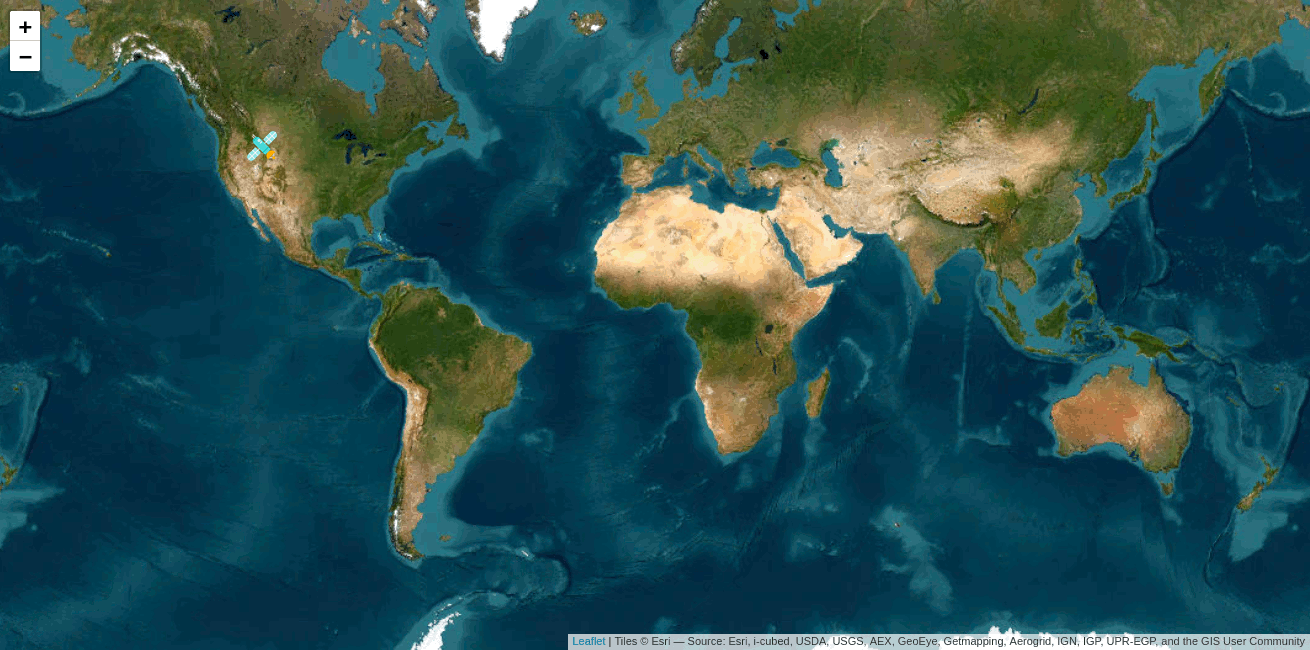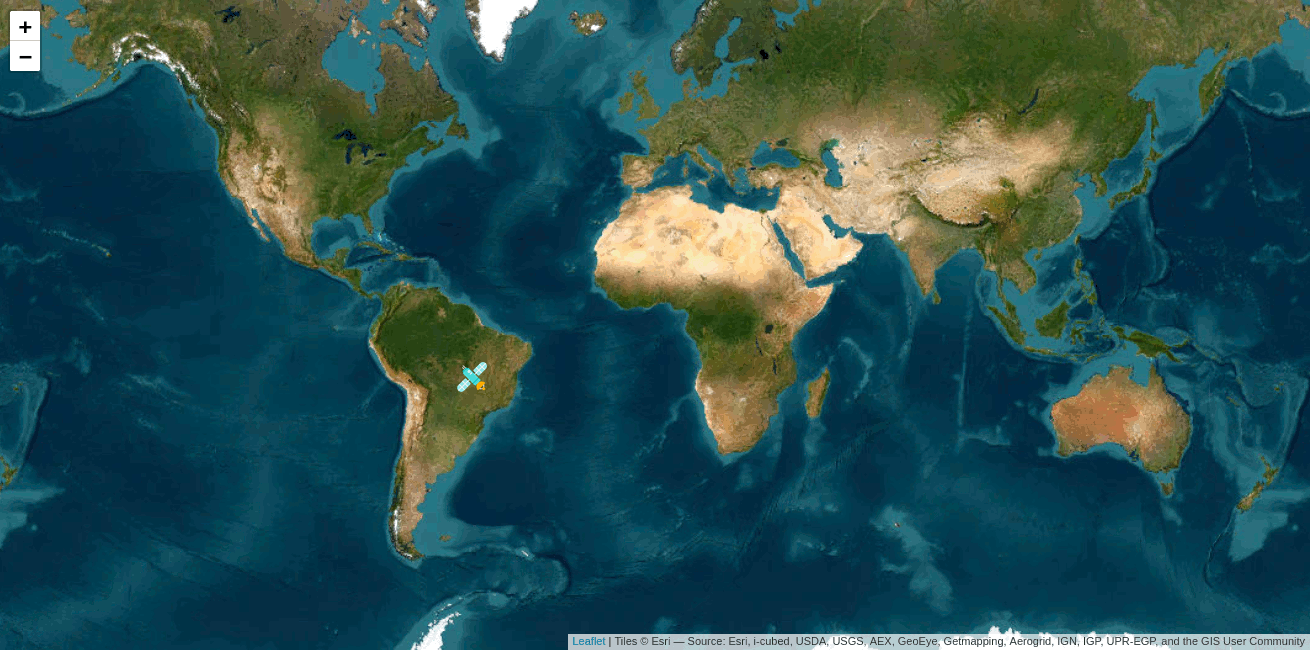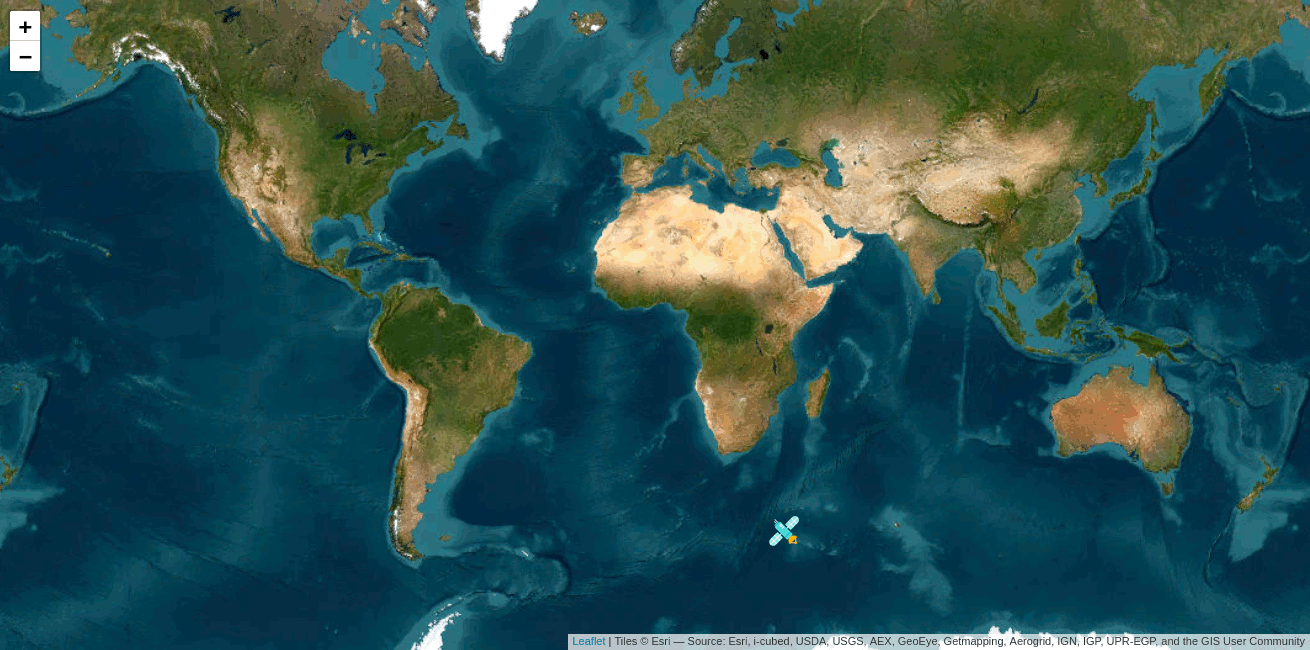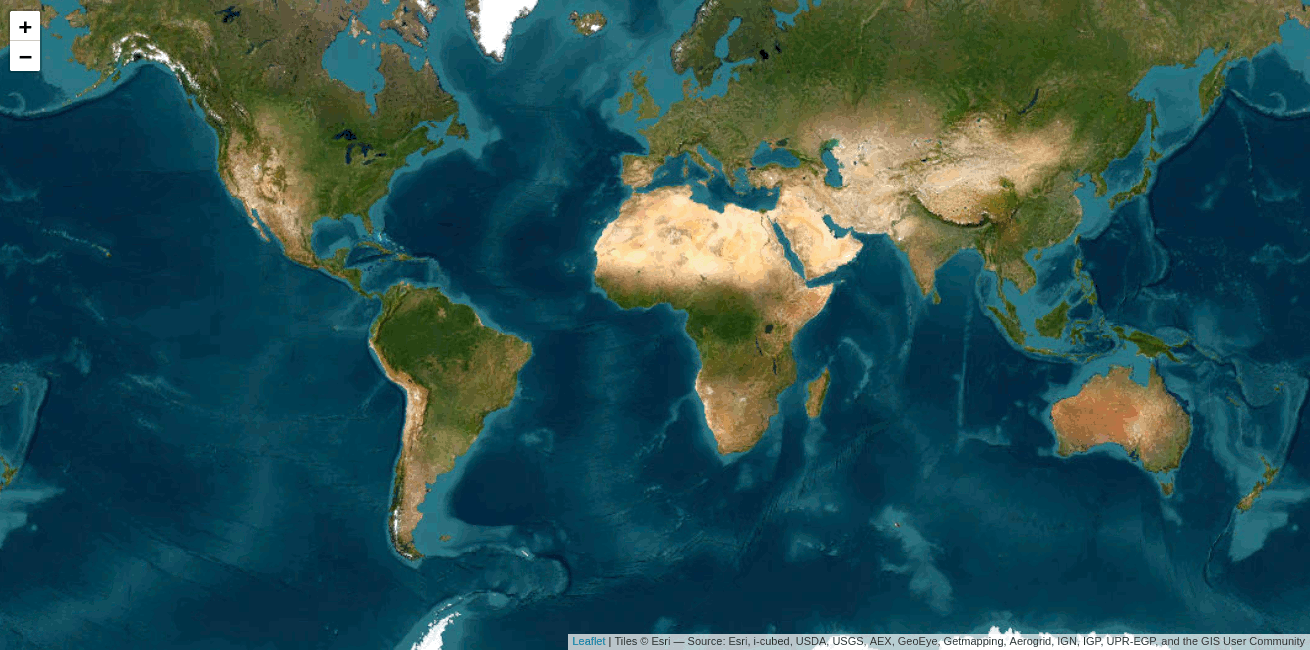
Paketnutzung
Interessierte können kafka hier selbst ausprobieren. Detaillierte Anleitungen zum Set-Up eines Kafka-Clusters, sowie zum Producer und Consumer befinden sich in der README. Dort enthalten ist auch der vorgestellte Code inklusive einer umfangreicheren Variante.
Zusammenfassung
In diesem Artikel haben wir kafka vorgestellt: ein Paket, das R-basierte Kafka-Integrationen ermöglicht. Dabei haben wir anhand von Live-Standortdaten demonstriert, wie produziert und konsumiert wird. Kafka gewährleistet Datenintegrität selbst bei Ausfällen seiner Broker und ist daher ein leistungsstarkes und sicheres Tool für Echtzeitanwendungen.
Wir freuen uns, wenn kafka von Nutzer*innen getestet wird und seinen Mehrwert zeigen kann.