Reflektion der US-Wahlprognose 2020 - 10 Dinge, die Data Scientists wissen sollten
Die US-Präsidentschaftswahlen 2020 im vergangenen November waren das wichtigste politische Ereignis des letzten Jahres. Politikwissenschaftler und Data Scientists hatten die Gelegenheit, Prognosemodelle zu entwickeln, um das Verhalten der amerikanischen Wähler angesichts der politischen Umwälzungen und der zunehmenden Unzufriedenheit in einem bipolarisierenden politischen Ökosystem der USA zu verstehen und vorherzusagen. Die Diskurse und die Literatur über die richtige Vorhersage der US-Wahlen werden immer noch heiß diskutiert. Wenn man die Prognosemethodologie von The Economist mit dem Prognosemodell von Nate Silver bei FiveThirtyEight vergleicht, gibt es 10 wichtige Dinge, die jeder Data Scientist beachten sollte.
1. Die Vorhersagekraft grundlegender wirtschaftlicher Faktoren sollte kritisch hinterfragt werden
Eine Seite behauptet, dass fundamentale Merkmale (wirtschaftliche Merkmale wie Aktienmärkte, BIP usw.) gute Prädiktoren für das Wahlverhalten sind, wenn diese Informationen mit den parteipolitischen Neigungen kombiniert werden. G. Elliot Morris von The Economist argumentierte, dass fundamental-basierte Prognosen konsistenter und stabiler sein können. Der Economist ist der Ansicht, dass die Ergebnisse alles andere als perfekt, aber beim Versuch zurückliegende Wahlen vorherzusagen, beeindruckend zuverlässig sind. Im Gegenteil, einige argumentieren, dass diese Prädiktoren dazu neigen, das Modell überanzupassen, was zu einer geringeren Genauigkeit führt, da fundamentale Daten für die Vorhersage sich ständig ändernder Wahlergebnisse verwendet werden. Der Data Science-Experte Marcus Groß von INWT Statistics teilt die gleiche Besorgnis und fragt, ob Wirtschaftsdaten implizit in die Umfragedaten eingebacken werden, um dem Modell redundante Wirtschaftsinformationen zum Lernen zu liefern. Darüber hinaus verwendete das FiveThirtyEight-Modell eine Ensemble-Prognosemethode, die sich aus drei Regressionen zusammensetzt: 1) parteipolitische Neigung der Bundesstaaten, 2) demografische Regression, 3) regionale Regression. Das Modell von FiveThirtyEight hängt stark von der Rekalibrierung der Umfragedaten ab, um die Nuancen des Wählerverhaltens zu berücksichtigen: 1) wahrscheinliche Anpassung der Wähler (likely voter adjustment), 2) Anpassungen der Hauseffekte (house effects adjustments) und 3) Effekte von zukünftige Ereignissen (timeline-stimulants adjustments) z.B. durch politische Debatten.
2. Das Abwägen der Einbeziehung von Wirtschaftsdaten hängt davon ab, wie wir den Trade-Off zwischen politischer Polarisierung und den aktuellen Handelskonflikten wahrnehmen
Der Economist behauptet, man sollte Wirtschaftsdaten einbeziehen, wenn Amtsinhaber zur Wiederwahl kandidierten, da die Auswirkungen des wirtschaftlichen Erfolgs einer Amtszeit die Präferenz der Wähler erheblich beeinflussen könnten. FiveThirtyEight stellte fest, dass die "Wirtschaft nur etwa 30 Prozent der Schwankungen in der Leistung der etablierten Partei erklärt, was bedeutet, dass andere Faktoren die anderen 70 Prozent erklären." Diese Feststellung deutet möglicherweise darauf hin, dass Präsidenten ihre wirtschaftlichen Hinterlassenschaften nicht an die Nachfolger ihrer Parteien vererben. Darüber hinaus ist die Feststellung, dass "das Ausmaß dieses Effekts in den letzten Jahren geschrumpft ist, weil die Wählerschaft polarisierter geworden ist", umstritten, wenn man bedenkt, wie sich der Handelskrieg zwischen den USA und China in den letzten Jahren auch auf die Perspektiven vieler Amerikaner ausgewirkt hat. Die Behauptung, dass es weniger „Swing-Wähler“ gibt, deren Entscheidungen von den wirtschaftlichen Bedingungen bestimmt werden, bleibt aufgrund der jüngsten Handelsspannungen ebenfalls fraglich. In welchem Ausmaß wir Wirtschaftsdaten einbeziehen sollten, hängt davon ab, wie wir die Auswirkungen des Trade-Offs zwischen der Polarisierung der Wähler und den aktuellen geopolitischen Handelskonflikten wahrnehmen.
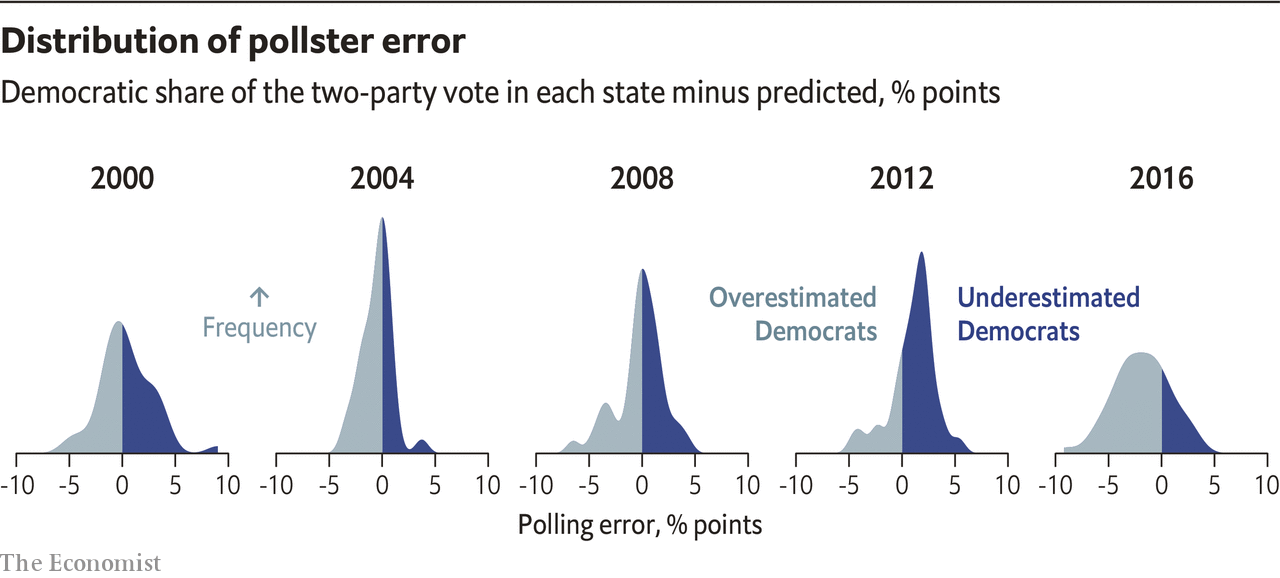
3. Umfragen sind anfangs schwach, aber werden stärker, je näher der Wahltag rückt
Data Scientists sollten die Limitationen von Umfragedaten verstehen. Angesichts der Tatsache, dass Umfragen bei demokratischen Wahlen die Wahlentscheidung der Bürger erfassen, haben Data Scientists diese Daten kürzlich auf sehr kreative Weise für Feature-Engineering verwendet. Wenn man den Einfluss des zentralen Grenzwertsatzes versteht, so ist klar, dass Umfragen anfangs schwache Informationen für die Vorhersage des endgültigen Wahlergebnisses liefern. Das Prognoseteam vom Economist warnt davor, dass frühe Umfragestatistiken zwangsläufig zu Verzerrungen und Fehlern führen können. Andererseits sagt der Data Scientist Marcus Groß von INWT Statistics, dass „frühe Umfragen keine wirkungsvollen Ereignisse zwischen dem Umfragedatum und dem Wahldatum beinhalten und spätere Umfragen nur präziser sind, wenn sie sich dem Wahltag nähern“, was bedeutet, dass sie die Unsicherheit unterschätzen könnten, da sie keine zukünftigen Ereignisse berücksichtigen.
 Quelle: The Economist - How The Economist presidential forecast works
Quelle: The Economist - How The Economist presidential forecast works
4. Umfragen sind Momentaufnahmen, keine Prognosen
Das FiveThirtyEight-Modell aggregierte die Umfragen in jedem Bundesstaat, um den aktuellen Stand widerzuspiegeln. Hier ein paar Tipps zum ordnungsgemäßen Umgang mit Umfragedaten: Seien Sie vorsichtig bei gefälschten Umfragen, vermeiden Sie Umfragen, die von Hobbyisten online in Auftrag gegeben wurden, vermeiden Sie Umfragen, bei denen Daten mithilfe der multiplen Regression mit Postratification (MRP) Dritter gemischt oder geglättet werden, und schließen Sie Umfragen aus, die hypothetische Testkandidaten berücksichtigen. Sobald wir unsere zuverlässigen Umfragedaten haben, können wir zwischen zwei allgemeinen Methoden zur Mittelung der Umfragen entscheiden: 1) einen einfachen Durchschnitt der letzten Umfragen oder 2) eine Ensemble-Methode, die die Umfragen zu Trendlinien kombiniert. Das FiveThirtyEight-Modell verwendete einen Hybrid aus beiden. Daraus kann mitgenommen werden, dass Umfragen eher einen "Ist-Zustand" anstelle einer "Prognose" liefern, weil sie Fragen beantworten wie "Was wäre, wenn die Wahlen heute statt im November wären", sagt Marcus Groß.
5. Die zunehmende Polarisierung des amerikanischen politischen Ökosystems kann sich auf die Prognose auswirken
Die politische Polarisierung behindert die Wirksamkeit der Umsetzung politischer Maßnahmen. Im Laufe der Jahre hat die Polarisierung in der US-Regierung zwischen den Parteien zugenommen. Eine Methode zur Modellierung der Polarisierung besteht darin, die institutionellen Mechanismen der US-Regierung aufzuschlüsseln. Zu berücksichtigende Metriken umfassen Unterschiede im Mittel der Parteien, das Verhältnis der gemäßigten Demokraten gegenüber den Republikanern, die Unterschiede im Mittel der Kammern und die Unterschiede zwischen den regionalen demokratischen und den republikanischen Durchschnittswerten. Dies könnte zu weniger Unsicherheit führen, wenn wir einige demokratische Variablen konstant halten. Andere Möglichkeiten zur Modellierung der politischen Polarisierung umfassen die Verwendung parametrischer Bootstrap-Standardfehler, die als sog. "DW-Nominate Scores" bezeichnet werden und mehrere Polarisationsdimensionen in den Sitzen des Repräsentantenhauses und des Senats berücksichtigen.
6. Der richtige Weg um Überanpassung zu vermeiden, ist die Kreuzvalidierung unter Berücksichtigung jedes Wahljahres
Data Scientists verwenden seit langem die Kreuzvalidierung, um eine Überanpassung des Modells zu verhindern. Für diese Wahlvorhersage sollten wir jedoch innovativere Methoden zur der Kreuzvalidierung in Betracht ziehen. Das Vorhersagemodell vom Economist verwendete die Techniken "elasticity net regularization” und "leave-one-out Kreuzvalidierung", bei denen jede Teilmenge als Daten eines Wahljahres sind. Unter Verwendung fundamentaler Daten aus dem Jahr 1948 erstellten sie ein Modell, das mit einer 17-fachen Kreuzvalidierung trainiert wurde, wobei jede Teilmenge eine der Präsidentschaftswahlen ab dem Jahr 1948 darstellt. Anschließend hält das Modell die Daten jeder Wahl bereit und verwendet sie um die Ergebnisse der Holdout-Stichprobe bei den bevorstehenden Wahlen vorherzusagen. Für die Optimierung des Modells wurden insgesamt 18 Prognosen für jedes Präsidentschaftswahljahr erstellt, um schließlich das Ausmaß der Shrinkage zu optimieren und so das Modell auszuwählen, das die besten Ergebnisse auf Basis der Holdout-Wahldaten erzielt.
7. Die Unsicherheit von COVID-19 auf die Entscheidung der Wähler ist schwer zu quantifizieren
Die Geschichte wiederholt sich nicht, aber manchmal reimt sie sich. Es gibt Methoden, um zu quantifizieren, wie sich Pandemien auf die Entscheidung der Wähler in der Geschichte auswirkten. Aber die Auswirkungen von COVID-19 auf die politische Ausrichtung der Bürger, die wirtschaftlichen Aussichten und die Entscheidungsfindung auf staatlicher Ebene sind noch unklar. Das Economist-Modell hat die wirschaftliche Rezession, die von der COVID-19 Pandemie verursacht wurde, berücksichtigt und dann ihren Wirtschaftsindex entsprechend den Grenzen der Daten angepasst, auf denen das Modell trainiert wurde. Andererseits hat das Modell von FiveThirtyEight zwei COVID-19-bezogene Variablen für das Feature-Engineering untersucht: 1) wirtschaftliche Unsicherheit 2) Gesamtvolumen der COVID-19-bezogenen Nachrichten. Darüber hinaus erlaubte FiveThirtyEight COVID-19 als Prädiktor, der einen Kovarianz-Score durch Factoring von Staaten mit hohen COVID-Todesraten bestimmte.
8. Die Modellierung des Wahlverhaltens in den Swing States ist keine leichte Aufgabe
Die Vorhersage parteilicher Neigungen ist der Schlüssel zum Verständnis des amerikanischen politischen Systems. Im Gegensatz zu Deutschlands und Frankreichs proportionalem System oder anderen EU-Wahlsystemen verwenden die USA "The-Winner-Takes-All", das dem Vorhersage-Team Hinweise gibt, wie jeder Staat durch eine parteipolitische "Neigung" aufgeschlüsselt werden kann. Dies ist der Grad der Präferenz jedes Staates für Demokraten oder Republikaner im Vergleich zur durchschnittlichen Präferenz der Amerikaner im jeweiligen Staat, auch "Swingness". Anschließend wird die Berechnung der Wahrscheinlichkeit, dass jeder Kandidat eine Stimme gewinnt, in den Score zur politischen Neigung umgewandelt. FiveThirtyEight verwendet einen „Swing Elasticity Score Index“, um die erwartete Neigungsänderung eines Staates basierend auf Änderungen auf nationaler Ebene widerzuspiegeln. Die Modellierung des „Uniform Swing“ zeigt die Beziehungen zwischen der Variation der nationalen Popularität der Kandidaten und der Fähigkeit der einzelnen Staaten, auf Änderungen der Popularität zu reagieren.
9. Ein Mix-Modell-Ansatz zur Verwendung von Umfragedaten und grundlegenden Daten könnte eine Lösung sein
Die jüngsten Wahlen zeigen, dass die Umfragedaten genauer in Bezug auf die tatsächliche Wahlentscheidungen der Bürger geworden sind. Das Modell des Economist nutzt diesen Trend, indem es den fundamentalen Daten weniger Gewicht und den nationalen Umfragedaten mehr Gewicht beimisst, je näher der Wahltag rückt. Unabhängig davon, ob der Kandidat amtiert oder wie stark die Wirtschaft das Wahlergebnis beeinflusst, liegt es im Ermessen des Data Scientists, fundamentale Daten, Umfragedaten oder beides einzubeziehen. Die Vorhersagekraft beider Datenquellen könnte möglicherweise in einem Modell resultieren, das die besten Ergebnisse liefert. Das FiveThirtyEight-Team hat beide Datenquellen kombiniert, indem es die Umfrageschätzungen basierend auf demografischen Merkmalen und früheren Abstimmungsmustern gemittelt hat. Als nächstes betrachtet das Modell die Priors aus grundlegenden Wirtschaftsdaten (Arbeitsplätze, Ausgaben der Haushalte, Einkommen, Produktion, Inflation und Aktienmärkte) sowie demografischen Daten (Religion, ethnische Herkunft, Einkommen, Bildung, Urbanisierung), um eine Prognose zu erstellen. Das FiveThirtyEight-Modell kombiniert eine Form des Parteipolitischen-Neigungs-Index, demografischer Regressionsmodellierung und regionaler Regressionsanalyse (Nordosten, Mittlerer Westen, Süden, Westen) und berücksichtigt eine Reihe komplexer Variablen und Anpassungen für die Wahl. Schließlich wurden jedes Mal, wenn das Modell aktualisiert wurde, etwa 40.000 Simulationen durchgeführt, in denen diese Merkmale analysiert wurden: Religion, parteipolitische Neigung des Staates, Breitengrad und Längengrad, Region, Stadt / Land, Durchschnittseinkommen, Alter, Geschlecht, Bildung und Einwanderung. Während The Economist in der Anfangsphase der Wahl stark von fundamentalen Daten abhängig war und dann mit näher rückenden Wahltag langsam mehr Gewicht auf die Umfragedaten legte, hat das FiveThirtyEight-Modell von Anfang mehr Gewicht auf Umfragedaten gelegt.
10. Zu wissen, welche Arten von Unsicherheit zu welchen Arten von Fehlern beitragen, ist entscheidend für die Prognosegenauigkeit
Das Modell von Nate Silver (FiveThirtyEight) berücksichtigt speziell vier Arten von Unsicherheiten, die die Vorhersagefehlerrate erhöhen könnten: National Drift (Unterschied von erwartetem und tatsächlichem Wert zwischen der Momentaufnahme und dem Wahltag), National Election Day Error (endgültige Prognose im Vergleich zu den tatsächlichen Ergebnissen), Correlated State Error (Fehler, der in mehreren Staaten entlang geografischer oder regionaler Domänen auftreten kann) und State-specific Error (Prognosegenauigkeit für jeden Staat). In ähnlicher Weise hat unser Wahlprognosemodell von INWT Statistics in der Prognose für die Bundestagswahl 2017 auch viele Arten von Unsicherheiten erfasst. Zum Beispiel die Unsicherheit bei Einzelumfragen, die Unsicherheit bei Gesamtumfragen, die Unsicherheit aufgrund zukünftiger Ereignisse und die Vorurteile gegenüber Umfrageinstituten. Wahlprognosen für andere Länder sollten nicht nur das US-Wahlmodell kopieren, sondern auch kreative Wege finden und neue Methoden entwickeln, die mit den Nuancen ihrer eigenen politischen Systeme verbundenen Unsicherheiten zu quantifizieren.
Zusammenfassend lässt sich sagen, dass sich diese 10 Punkte auf die bevorstehenden Wahlen anderer Demokratien übertragen lassen. Für die bevorstehenden Bundestagswahlen im September 2021 schlägt Marcus Groß vor, keinen Mix-Modell-Ansatz zu implementieren, da weniger Datenpunkte verfügbar sind (weniger Daten auf regionaler Ebene, weniger alte Umfragedaten), ein struktureller Bruch in der deutschen Einheit liegt, und komplexere Dynamik durch Mehrparteiensystem vorhanden ist. Darüber hinaus schlägt Groß vor, einen "Long-short-term Voter Memory" Ansatz als Alternative zum Mix-Modell-Ansatz für die US-Wahlen zu verwenden, da er andere Methoden zur Quantifizierung der Unsicherheit bietet. Letztendlich ist es Sache des Data Scientists, innovativ zu werden, wenn diese Modelle auf die eigenen nationalen Wahlen angewendet werden. Dabei sollten sich Statistiker und Data Scientists der Unterschiede und politischer struktureller Nuancen bewusst sein, die ihre Prognosen komplexer und unsicherer machen könnten.