Reinforcement Learning für Marketing: Lektionen und Herausforderungen
Was ist Reinforcement Learning (RL)?
Beim Reinforcement Learning kann ein „Agent“ innerhalb einer „Umgebung“ verschiedene Aktionen durchführen und gezielt Maßnahmen aus einem vorgegebenen Set ergreifen. Im Gegensatz zu vielen Algorithmen aus dem Bereich Machine Learning, die nur einen einzigen Schritt umfassen, ist Reinforcement Learning ein iterativer Prozess: Der Agent sieht seine aktuelle Situation (seinen Zustand in der dazugehörigen Umgebung) und ergreift darauf basierend über diskrete Zeitabschnitte hinweg wiederholt Maßnahmen.
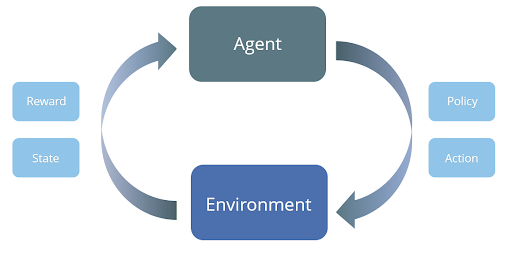
Wenn die konkrete Aktion einen positiven Effekt hat, wird der Agent belohnt. Dadurch kann er herausfinden, welche Aktionen in den entsprechenden Situationen zu den besten Ergebnissen führen. Das Feedback kann dem Agenten direkt nach jeder Aktion oder kumuliert nach dem Treffen wiederholter Entscheidungen am Ende seiner Journey gegeben werden. Unabhängig davon besteht das Ziel des Agenten darin, sein langfristiges Ziel durch die Bewertung aller Schritte auf dem Weg dorthin zu optimieren. Dies bedeutet, dass bei jedem Schritt auf strategische Weise Maßnahmen ergriffen werden, um lang- oder längerfristige Ziele zu erreichen.
Was hat RL mit Online-Marketing zu tun?
Beim herkömmlichen data-driven Online-Marketing besteht das Ziel darin, eine kurzfristige Reward zu maximieren: Beispielsweise in der Auswahl einer Aktion (wie dem Versenden eines Newsletters oder Gutscheins), die einen bestimmten KPI (z. B. Kaufwahrscheinlichkeit, CTR, erwarteter Gewinn usw.) innerhalb eines bestimmten Zeitraums maximiert.
Im Gegensatz dazu zielen die Methoden des Reinforcement Learnings darauf ab, Maßnahmen auszuwählen, die den langfristigen Erfolg maximieren. Es könnte sein, dass sich Marketingaktionen erst verzögert oder im Zusammenspiel mit weiteren Aktivitäten langfristig auswirken. Vielleicht ist es sinnvoll, zunächst einen Banner auszuspielen und mit zeitlicher Verzögerung zusätzlich einen Rabattcode anzubieten. Dies kann effektiver sein, als dem Kunden direkt und ausschließlich den Rabatt zu gewähren. Solche Ergebnisse und situationsbedingten Wechselwirkungen können aufgrund ihrer Komplexität bei einem Modell, das lediglich auf den unmittelbaren kurzfristigen Reward abstellt, leicht übersehen werden.
Wir können die Anwendung des RL-Framework im digitalen Marketing anhand des Customer Lifetime Value (CLV) illustrieren. Ziel einer CLV-Analyse ist es, zu prognostizieren, wie viel Umsatz in der gesamten Dauer einer Kundenbeziehung mit einem Unternehmen erzielt werden wird. Somit ist es sinnvoll, dass eine fundierte CLV-Analyse eine langfristige Perspektive auf das Kundenverhältnis einnimmt, um in einer sich dynamisch ändernden Umgebung möglichst exakte Vorhersagen über die zeitliche Entwicklung der Kundenbeziehung zu treffen.
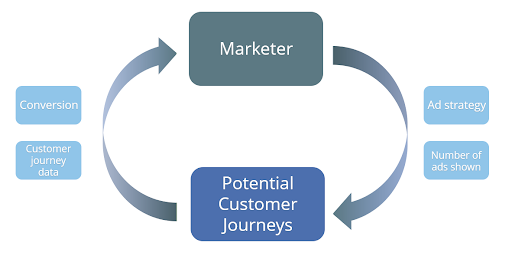
In einem solchen Beispiel besetzt der Marketer die Rolle des Agenten und die Umgebung, in der sich das Kundenverhältnis entwickelt, ist die Menge aller möglichen Customer Journeys (CJ). Die Aktionen, aus denen der Marketeer wählen kann, sind dann z.B. Anzahl und Art des Werbemitteleinsatzes für die jeweiligen Kunden. Zu jedem Zeitpunkt bewertet der Agent den Status seiner Kunden und entscheidet, wie die individuellen Marketingaktionen aussehen, die das langfristige Conversionziel maximieren.
Generell unterscheidet man zwei Arten des RL: Online- und Batch-RL. Beim Online-Reinforcement Learning werden die Daten in Echtzeit erfasst, die Ergebnisse unterschiedlicher Strategien evaluiert und die Strategie entsprechend angepasst. Im Gegensatz dazu funktioniert das Batch-Reinforcement Learning in einem Setting, in dem zuerst eine ausreichend große Datenmenge gesammelt wird. Nachgelagert wird auf dieser Datenbasis die optimale Strategie ermittelt. Dies kann in einem iterativen Prozess erfolgen, bei dem Daten wiederholt gesammelt und ausgewertet und die Strategie angepasst werden.
Anwendung
Wir haben erprobt, wie sich das Konzept des Batch-Reinforcement Learning auf Customer Journey-Daten anwenden lässt. Mögliche Aktionen waren das Schalten von Werbeanzeigen zu bestimmten Zeitpunkten in der CJ. Bei der Berechnung des Rewards wurden die Conversion-Rate, die Werbemittelkosten und der erzielten Umsatz berücksichtigt. Diese Rewards und die Übergänge zwischen den Zuständen waren stochastischer Natur, d.h. sie wurden über die Erwartungswerte eines statistischen Modells abgebildet. Das spiegelt den Sachverhalt wider, dass sich auch echte Kunde nicht deterministisch verhalten, sondern bestimmte Entscheidung auch unbewusst und somit für Außenstehende zufällig treffen.
Die für die Schätzung des RL-Algorithmus verwendete Methode war Q-Learning. Hierbei handelt es sich um einen modellagnostischen Algorithmus, mit dem ein Regelwerk erlernt wird, das dem Agenten mitteilt, welche Maßnahmen unter welchen Umständen optimalerweise zu ergreifen sind. Es erfordert keine Modellierung der Umgebung (d.h. des Raums aller möglichen CJs) und kann Probleme mit stochastischen Übergängen und Rewards bewältigen. Q-Learning kann mit verschiedenen Deep Learning- (Deep-Q-Learning) oder Machine Learning-Modellen wie Random Forests oder Gradient Boosting kombiniert werden. Im konkreten Projekt haben wir auf Gradient Boosting (XGBoost) gesetzt, da es state-of-the-art Performance mit einem hohen Maß an Interaktionen für tabulare Daten bietet.
Ergebnisse
Im folgenden wollen wir diskutieren, was wir aus diesem Projekt für den Einsatz von RL im Online Marketing lernen konnten.
Batch Reinforcement Learning stellt Herausforderungen
Aufgrund der technischen Komplexität scheidet Online Reinforcement Learning vermutlich für den Einsatz in einem Großteil an Unternehmen aus, so dass Batch RL eine interessante Alternative bietet. Unser Learning aus dem durchgeführten Projekt ist, dass Batch RL aber auch mit Einschränkungen einhergeht:
- Um die optimale Abfolge an Aktionen im Rahmen des Batch-RL zu ermitteln, ist es zwingend notwendig, dass mit den erfassten Daten auch genügend Varianz (d.h. Streuung und Zufälligkeit) an Aktionen beobachtet wurde. Ist diese Streuung nicht gegeben,so kann das Modell nicht ermitteln, wie alternative Aktionen bzw. Aktionsabfolgen den langfristigen Reward beeinflussen. Ursächlich für eine solch fehlende Varianz in den Batch-Daten können z.B. starre oder gesättigte Marketingkampagnen sein.
- Für Batch-RL ist es desweiteren schwierig, den exakten Reward einer neu gefundenen Strategie zu ermitteln, da die Strategie ja nicht online angewandt und der tatsächliche Reward nicht direkt beobachtet werden kann. Damit birgt Batch-RL das Risiko den Reward der optimalen Strategie zu überschätzen.
- Für die Durchführbarkeit von RL-basiertem Online-Marketing ist es entscheidend, dass der Zustand und die Umgebung beobachtet und gespeichert und die Maßnahmen innerhalb eines sinnvollen Zeitraums angepasst werden können. Dies ist eine Herausforderung, da die Unsicherheit über den tatsächlichen Zustand eines Kunden immer mit Unsicherheit verbunden ist. Dies ist ein allgemeines Problem im Online-Marketing, das sich besonders stark auf das RL auswirkt. Beispielsweise weiß man nicht immer, ob ein Kunde tatsächlich einen Newsletter erhalten hat (möglicherweise in seinem Spam-Ordner) oder ob eine Bannerwerbung tatsächlich sichtbar war (wenn der Kunde einen AdBlocker verwendet oder nicht weit genug auf der Seite gescrollt hat). Dies macht es für das Modell schwierig, die besten Maßnahmen genau zu bestimmen.
- Um Marketingentscheidungen in Echtzeit treffen zu können, müssen alle Datenquellen integriert und verfügbar sein, sodass sofortige Anpassungen an Maßnahmen auf aktuellen Daten basieren. Beim Batch Reinforcement Learning ist es oft nicht möglich, die optimale Strategie rechtzeitig umzusetzen, selbst wenn man Klarheit über den Status des Kunden hat.
Die Definition von Zeitschritten und Zuständen ist inkonsistent
Das RL erfordert die Definition diskreter Zeitschritte, in denen die Übergänge von einem Zustand in den nächsten erfolgen. Im Online-Marketing sind diese Zeitschritte nicht immer eindeutig definiert. So müssen Zustandsübergänge an konkret beobachtbaren Ereignissen wie z.B. dem Besuch eines Online-Shops, etc festgemacht werden.Inwieweit diese Beobachtungen jedoch auch wirklich Zustandsänderungen beim Kunden abbilden, muss im Einzelfall diskutiert und sachlogisch bewertet werden.
Fazit
Während RL sicherlich eine interessante und vielversprechende Methode ist, scheint es angesichts des aktuellen technologischen Umfelds wahrscheinlich, dass es nur von größeren Unternehmen mit sehr fortschrittlicher Daten-Infrastruktur implementiert werden kann. Dies mag erklären, warum wir die weit verbreitete Einführung von RL in die Marketing-Welt bisher noch nicht gesehen haben, sondern diese noch hauptsächlich mit Methoden aus dem Bereich Supervised Machine Learning bespielt wird.