Text Mining – Part 3: Making-Of
Eine Sentiment-Analyse hat das Ziel, die Wahrnehmung (Polarität) eines Textes oder Tokens zu quantifizieren. Es wird demnach analysiert, ob der Text im Allgemeinen als positiv (Wörter wie z.B. “Glück”) oder negativ (z.B. “Verrat”) wahrgenommen wird oder eher neutral ist. Dies geschieht auf einer Skala von -1 bis 1, wobei -1 extrem negative und 1 extrem positive Begriffe widerspiegelt. 0 steht für Neutralität. Dabei gibt es verschiedene Abstufungen, beispielsweise wird das Wort “perfekt” von Menschen im Schnitt wesentlich positiver wahrgenommen als das Wort “zufrieden”, obwohl beide im positiven Bereich liegen.
Im zweiten Teil der Serie wurde beschrieben, wie die Wahlprogramme der sechs stärksten Parteien für ein Text-Mining vorbereitet wurden. Daraus resultierten Daten mit einem Wort (“Token”) pro Zeile. Um den Tokens der Wahlprogramme Sentiments zuweisen zu können, wird nun eine Art Wörterbuch importiert, das die Polarität für (viele, aber nicht alle) deutsche Wörter enthält. Vielen herzlichen Dank an die Uni Leipzig, die für diese Zwecke den Sentiment-Wortschatz (SentiWS) zur Verfügung stellt.
# Pakete laden
library("dplyr")
library("ggplot2")
library("magrittr")
Datenvorbereitung
Die Wörterbücher werden zunächst geladen und für die Weiterverarbeitung entsprechend aufgearbeitet.
# Wörter laden und vorbereiten
sent <- c(
# positive Wörter
readLines(paste0(FILEPATH, "SentiWS_v1.8c_Positive.txt"),
encoding = "UTF-8"),
# negative Wörter
readLines(paste0(FILEPATH, "SentiWS_v1.8c_Negative.txt"),
encoding = "UTF-8")
) %>% lapply(function(x) {
# Extrahieren der einzelnen Spalten
res <- strsplit(x, "\t", fixed = TRUE)[[1]]
return(data.frame(words = res[1], value = res[2],
stringsAsFactors = FALSE))
}) %>%
bind_rows %>%
mutate(words = gsub("\\|.*", "", words) %>% tolower,
value = as.numeric(value)) %>%
# manche Wörter kommen doppelt vor, hier nehmen wir den mittleren Wert
group_by(words) %>% summarise(value = mean(value)) %>% ungroup
Die Sentiments werden mittels eines Joins an die Tabelle mit den Tokens der Wahlprogramme angefügt. Für die Wörter in den Wahlprogrammen, für die kein Sentiment verfügbar ist, erhalten wir dadurch einen NA-Wert. Alle NAs werden entfernt.
sentTxt <- left_join(txt, sent, by = "words") %>%
mutate(value = as.numeric(value)) %>%
filter(!is.na(value))
Durchschnittliches Sentiment
Der Durchschnitt über alle Sentiments ergibt einen Indikator für die Gesamtwirkung der einzelnen Wahlprogramme. Dabei weist die AfD den negativsten Wert auf, knapp gefolgt von der Linken. Positive Durchschnittswerte sind nur für die beiden aktuellen Regierungsparteien zu beobachten:
sentTxt %>%
group_by(party) %>%
summarize(meanSent = mean(value))
## # A tibble: 6 x 2
## party meanSent
## <chr> <dbl>
## 1 AfD -0.053041256
## 2 CDU 0.028684718
## 3 FDP -0.014116642
## 4 Grüne -0.019918778
## 5 Linke -0.048160861
## 6 SPD 0.003802914
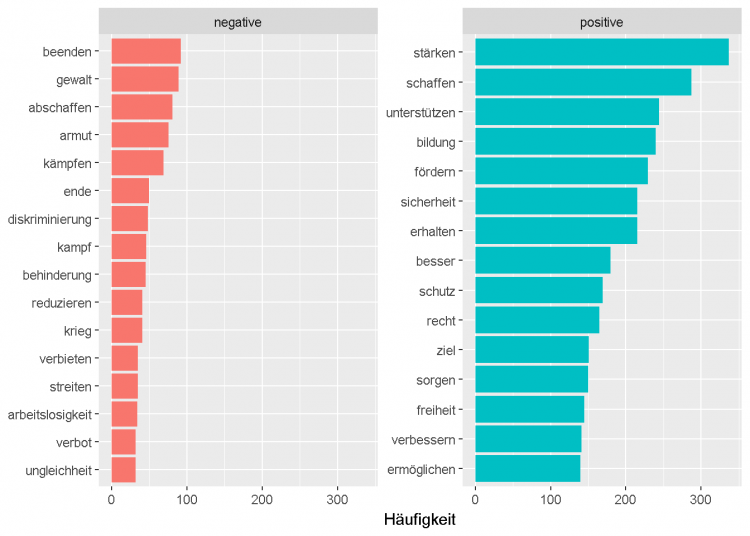
Häufigste positive und negative Wörter
Der folgende Plot zeigt die 15 positiven und negativen Wörter, die über alle Parteien hinweg am häufigsten verwendet werden.
sentTxt %<>%
mutate(sent = ifelse(value >= 0, "positive", "negative"))
sentTxt %>%
count(words, sent, sort = TRUE) %>%
ungroup %>%
group_by(sent) %>%
top_n(15, n) %>%
ungroup() %>%
mutate(word = reorder(words, n)) %>%
ggplot(aes(word, n, fill = sent)) +
geom_col(show.legend = FALSE) +
facet_wrap(~sent, scales = "free_y") +
labs(x = NULL, y = "Häufigkeit") +
coord_flip()
Positivste und negativste Wörter nach Partei
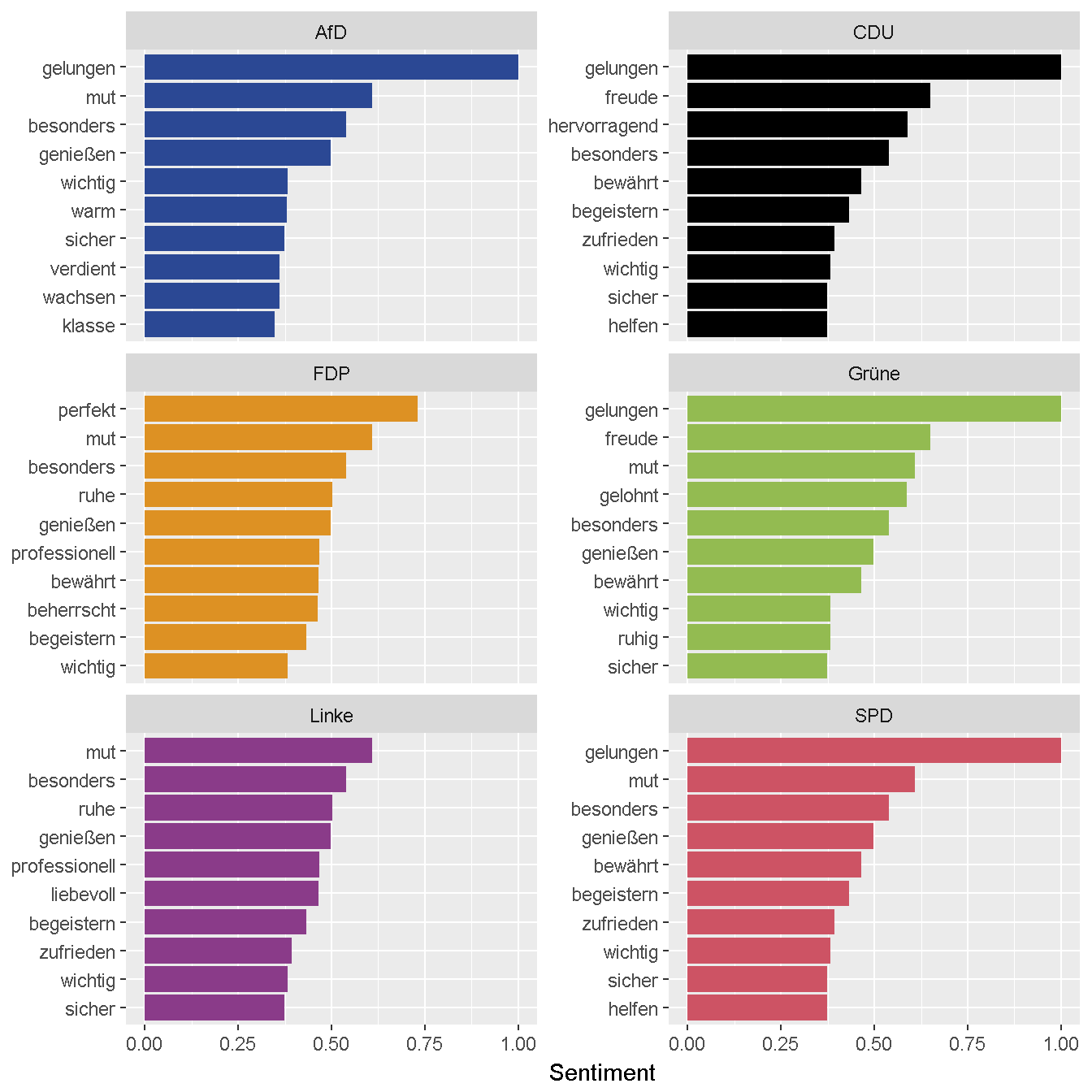
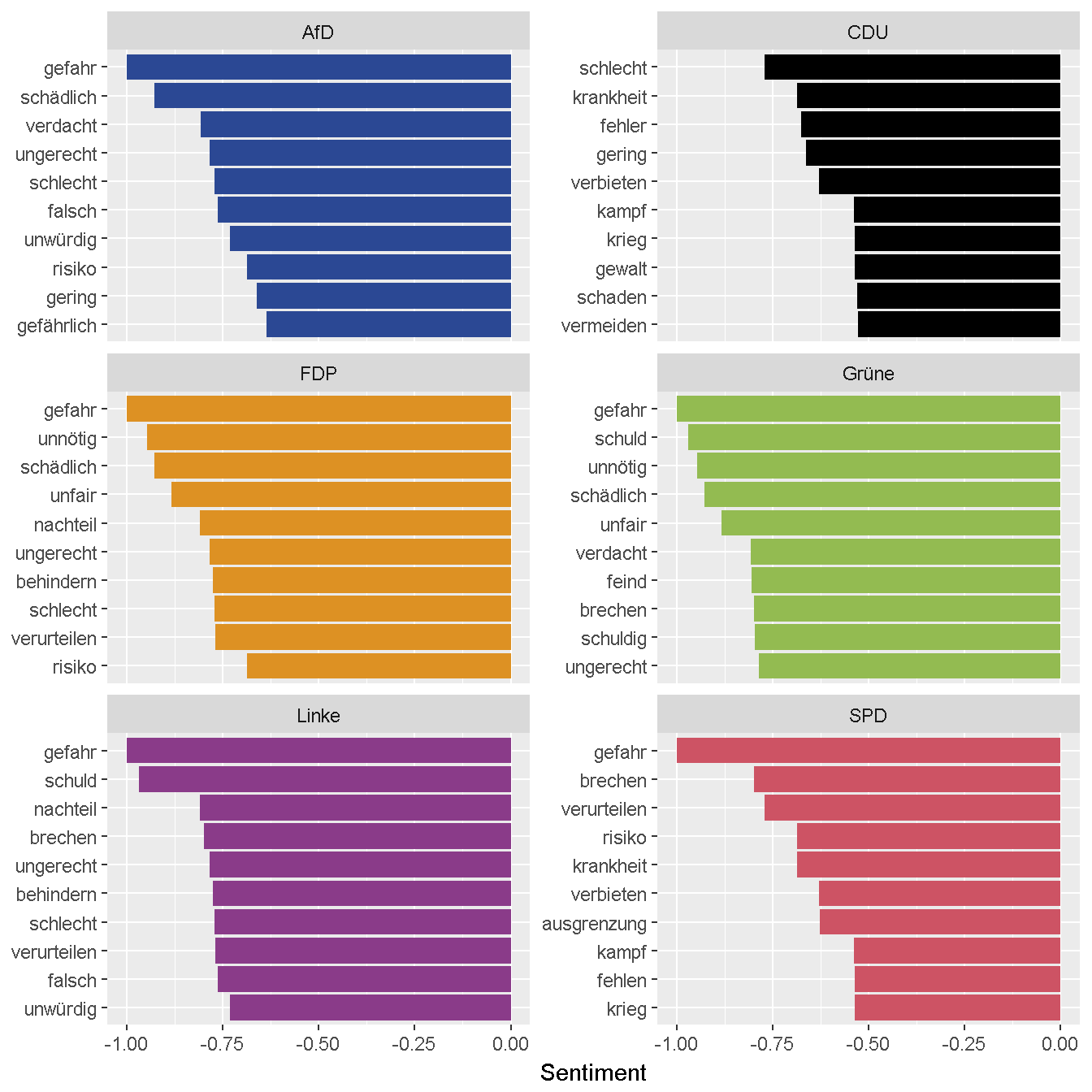
Die folgenden beiden Grafiken zeigen die jeweils zehn Wörter mit dem höchsten und niedrigsten Sentiment für jede Partei.
# Funktion zum Plotten
plotSentParty <- function(dat) {
dat %>%
ggplot(aes(words, value, fill = party)) +
geom_col(show.legend = FALSE) +
labs(x = NULL, y = "Sentiment") +
facet_wrap(~party, ncol = 2, scales = "free_y") +
coord_flip() +
scale_fill_manual(breaks = names(partyColor), values = partyColor)
}
# positive Wörter nach Partei
sentTxt %>%
arrange(desc(value)) %>%
mutate(words = factor(words, levels = rev(unique(words)))) %>%
group_by(party) %>%
filter(!duplicated(words)) %>%
top_n(10, value) %>%
ungroup %>%
plotSentParty
# Negative Wörter nach Partei
sentTxt %>%
arrange(value) %>%
mutate(words = factor(words, levels = rev(unique(words)))) %>%
group_by(party) %>%
filter(!duplicated(words)) %>%
top_n(-10, value) %>%
ungroup %>%
plotSentParty
Quelle
R. Remus, U. Quasthoff & G. Heyer: SentiWS – a Publicly Available German-language Resource for Sentiment Analysis. In: Proceedings of the 7th International Language Ressources and Evaluation (LREC’10), pp. 1168-1171, 2010

