Data-Profiling - Standardanalysen auf Attributebene
Bei der Attributanalyse können verschiedene Methoden angewendet bzw. kombiniert werden, um Informationen zu Inhalt, Struktur und Qualität von Daten zu gewinnen. Die folgende Liste zeigt eine Auswahl an möglichen Standard-Methoden:
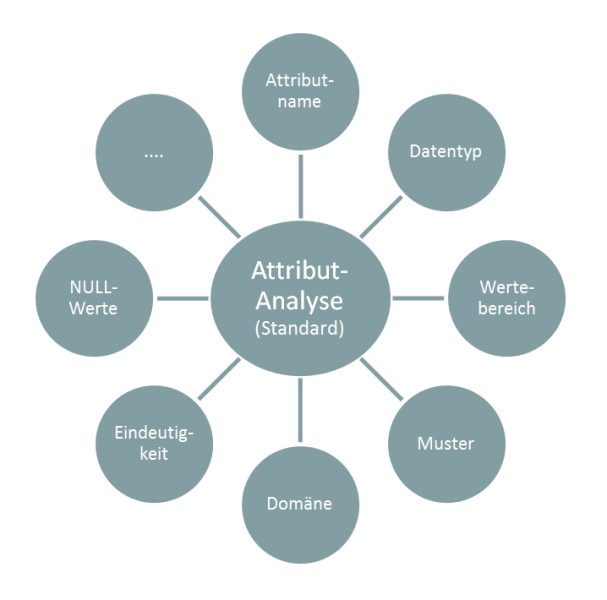
- Attributnamen-Analyse: Diese Analyse bezieht sich auf die Attributbezeichnung. Hintergrund ist, dass Attributbezeichnung und Inhalt der Daten übereinstimmen sollen. Befindet sich beispielsweise in der Attributbezeichnung ein Hinweis auf den Datentyp, sollte dieser auch mit dem Inhalt übereinstimmen (z.B. ist bei der Attribut-Endung „_Nr“ mit einem numerischen Wert zu rechnen).
- Datentyp-Analyse: Diese Analyse untersucht den Datentyp des Attributs. Wurden z.B. in ein Float-Datentyp-Feld nur binäre Daten gespeichert? Besteht eine Diskrepanz zwischen dem dokumentierten und dem dominanten Datentyp? Wie verteilt sich die Genauigkeit (z.B. Anteil der dominanten Datenlänge zum Anteil der minimalen Datenlänge)?
- Wertebereich-Analyse: Hier werden verschiedene statistische Kennzahlen zur Analyse der Daten eingesetzt (Minimum, Maximum, Mittelwert, Häufigkeitsverteilung, Standardabweichung, etc.).
- Muster-Analyse: Diese Analyse untersucht das Muster der Daten. In der Praxis ist es z.B. weit verbreitet, dass die Vorwahl von Telefonnummern unterschiedlich abgetrennt wird. Falls eine Musteranalyse aufdeckt, dass innerhalb eines Attributs verschiedene Schreibweisen für eine Telefonnummer benutzt werden, ist es sinnvoll diese zu vereinheitlichen. Ein weiteres Beispiel in diese Richtung sind die diversen existierenden Datumsformate.
- Domänen-Analyse: Die Domänen-Analyse identifiziert zulässige Attributelemente. In der Regel werden nur mehrfach auftretende Elemente eines Attributs ausgewertet. Als Ergebnis entsteht eine Liste von Elementen, die Rückschlüsse auf die zugrunde liegenden Prozesse des Attributs geben kann. Beispiel: Bei der Analyse des Attributs Geschlecht wird festgestellt, dass ausschließlich die Ausprägungen Mann, Frau und Unbekannt vorkommen. Diese Erkenntnisse können nun direkt in eine Regel zur Validierung zukünftiger Werte überführt werden (es werden nur die genannten drei Werte zugelassen). Darüber hinaus vereinfacht solch eine Regel die spätere Aggregation von Attributelementen.
- Eindeutigkeits-Analyse: Bei der Analyse auf Eindeutigkeit geht es im Wesentlichen um das Auffinden von Duplikaten. Duplikate sind für jegliche Auswertungen und Prozesse gefährlich. So binden Duplikate in Adressbeständen z.B. unnötig Kapazitäten im Vertrieb, weil dieser ggf. mehrfach versucht der gleichen Person ein Produkt zu verkaufen. Die Frustration bei dem Gesprächspartner ist sicherlich auch nicht zu unterschätzen. Auf Auswertungsebene ergibt sich das Problem, dass Duplikate zu falschen Entscheidungen führen können (z.B. bei falschen Verkaufszahlen). Aus diesen Gründen ist zu gewährleisten, dass Datensätze eindeutig sind. Die Eindeutigkeit innerhalb einer Tabelle wird über ein sogenanntes Schlüsselattribut gewährleistet. Die Eindeutigkeit eines solchen Schlüsselattributs kann auf vier Ebenen vorkommen, auf die an dieser Stelle nicht weiter eingegangen wird.
- NULL-Werte-Analyse: Die NULL-Werte-Analyse untersucht ein Attribut auf die Anzahl von (versteckten) NULL-Werten. Die Ursache für einen NULL-Wert kann z.B. eine fehlende oder fehlerhafte Eingabe an der Datenquelle sein. Ein anderer Grund kann darin bestehen, dass eine Tabelle sukzessive durch verschiedene Prozesse aufgebaut wird. Ggf. wird ein Attribut dann erst zu einer späteren Zeit gefüllt werden. In jedem Fall beinhalten NULL-Werte für das Reporting enorme Gefahren. Beispiel: Der Umsatz von Kundensegmenten wird in einem Report gegenübergestellt. Einige Kundendaten besitzen NULL-Werte und können keinem Segment zugeordnet werden. Sie fallen aus der Auswertung heraus und führen bei der Unternehmensleitung zu Verwunderung: Warum stimmt der Gesamtumsatz unseres Unternehmens nicht mit der Summe der Umsätze über alle Kundensegmente überein?
Literaturhinweise:
- Apel, D. (2010). Datenqualität erfolgreich steuern: Praxislösungen für Business-Intelligence-Projekte. Hanser.
- Hildebrand, K., Gebauer, M., Hinrichs, H., & Mielke, M. (2009). Daten- und Informationsqualität. Springer Fachmedien.