Data-Profiling zu Beginn von Projekten mit Datenbezug
Für eine realistische Planung von Projekten werden verlässliche Aussagen über die Qualität von Daten benötigt. Eine frühzeitige Untersuchung der Datenqualität bewahrt vor unerwünschten Überraschungen, die den Aufwand des Projektes vergrößern und geplante Termine nach hinten verschieben können. Diese Artikelserie widmet sich dem Thema Data-Profiling in Datenbanken.
In der Praxis wird das Thema Datenqualität häufig ignoriert oder zumindest vernachlässigt. Viele Unternehmen gehen davon aus, dass gespeicherte Daten in einem konsolidierten Zustand vorliegen und sofort für Analysen nutzbar sind. Unsere langjährige Erfahrung zeigt jedoch, dass dies in den seltensten Fällen zutrifft. Insbesondere, wenn Daten bisher nur gespeichert und wenig oder gar nicht genutzt wurden, ist eine vorherige Überprüfung der Datenqualität eine unabdingbare Voraussetzung für die Datenanalyse. Eine unliebsame Wahrheit ist die Gültigkeit der sog. SISO-Regel ("shit in - shit out"). Eine Analyse kann stets nur so gut sein wie die verwendeten Daten.
Probleme hinsichtlich der Datenqualität sind oft ganz trivialer Natur (überraschend auftretende NULL-Werte, falsch oder uneinheitlich formatierte Datums-Formate, nicht zulässige Werte, ...). Während solche Probleme bei kleinen Datensätzen ohne ein formales Regelwerk im Rahmen der Auswertung noch automatisch auffielen, bleiben sie in Zeiten von "Big Data" unentdeckt. Nur eine der Analyse vorangehende systematische Prüfung der Datenqualität gewährleistet valide Analyse-Ergebnisse.
In der vorliegenden Artikelserie werden Kriterien vorgestellt, mit denen der Datenanalyst Informationen zu Inhalt, Struktur und Qualität von Daten gewinnen kann.
Sammeln von Informationen zu Inhalt, Struktur und Qualität von Daten
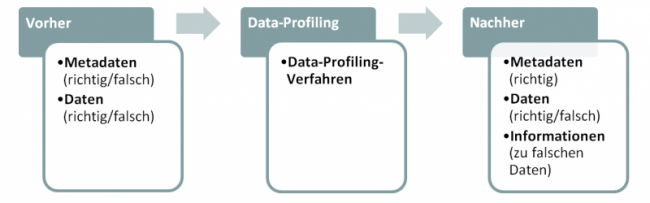
Um Informationen zu Inhalt, Struktur und Qualität von Daten zu gewinnen, werden Daten einem Data-Profiling-Prozess unterzogen. Aufgrund der Komplexität der Thematik kann innerhalb der vorliegenden Artikelserie nur ein kleiner Ausschnitt an möglichen Kriterien vorgestellt werden. Folgende Grafik fasst die Ziele des Data-Profilings zusammen:
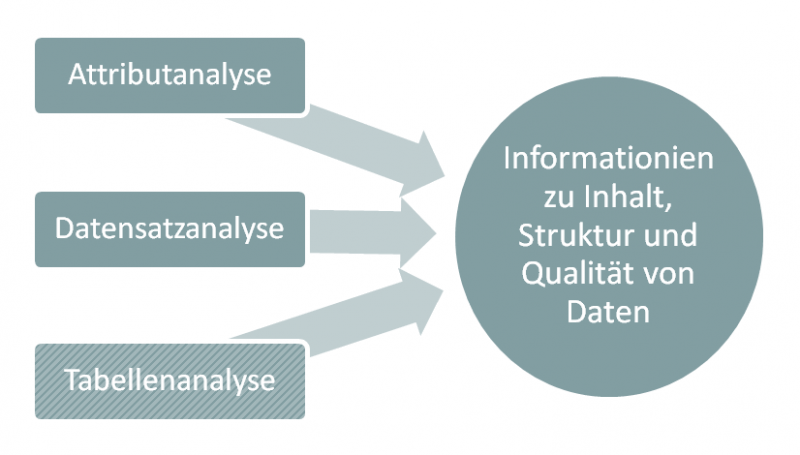
Data-Profiling-Verfahren können auf Attribut-, Datensatz- und Tabellen-Ebene durchgeführt werden. Auf Ebene von Attributen werden die Werte und Eigenschaften von Attributen (Spalten) einer Tabelle analysiert. Auf Datensatzebene werden alle Datensätze einer Tabelle analysiert und auf Tabellenebene die Beziehungen zwischen den Tabellen. Die Tabellenanalyse spielt natürlich nur für Daten eine Rolle, die über verschiedene Tabellen verteilt sind.
Literaturhinweise:
- Apel, D. (2010). Datenqualität erfolgreich steuern: Praxislösungen für Business-Intelligence-Projekte. Hanser.
- Hildebrand, K., Gebauer, M., Hinrichs, H., & Mielke, M. (2009). Daten- und Informationsqualität. Springer Fachmedien.